Folding@home — distributed volunteer computing for protein research
Folding@home is a long-running distributed computing project that uses volunteered computer power to simulate protein folding, study misfolding diseases and accelerate molecular research.
Overview
Folding@home is a distributed computing research project that harnesses the idle processing power of volunteer computers and devices to perform molecular dynamics simulations. Its primary scientific aim is to understand how proteins fold, how they can misfold or aggregate, and how those processes relate to disease. Volunteers run client software that downloads small simulation tasks, processes them locally, and returns results to a central research team for analysis.
Image gallery
10 Images
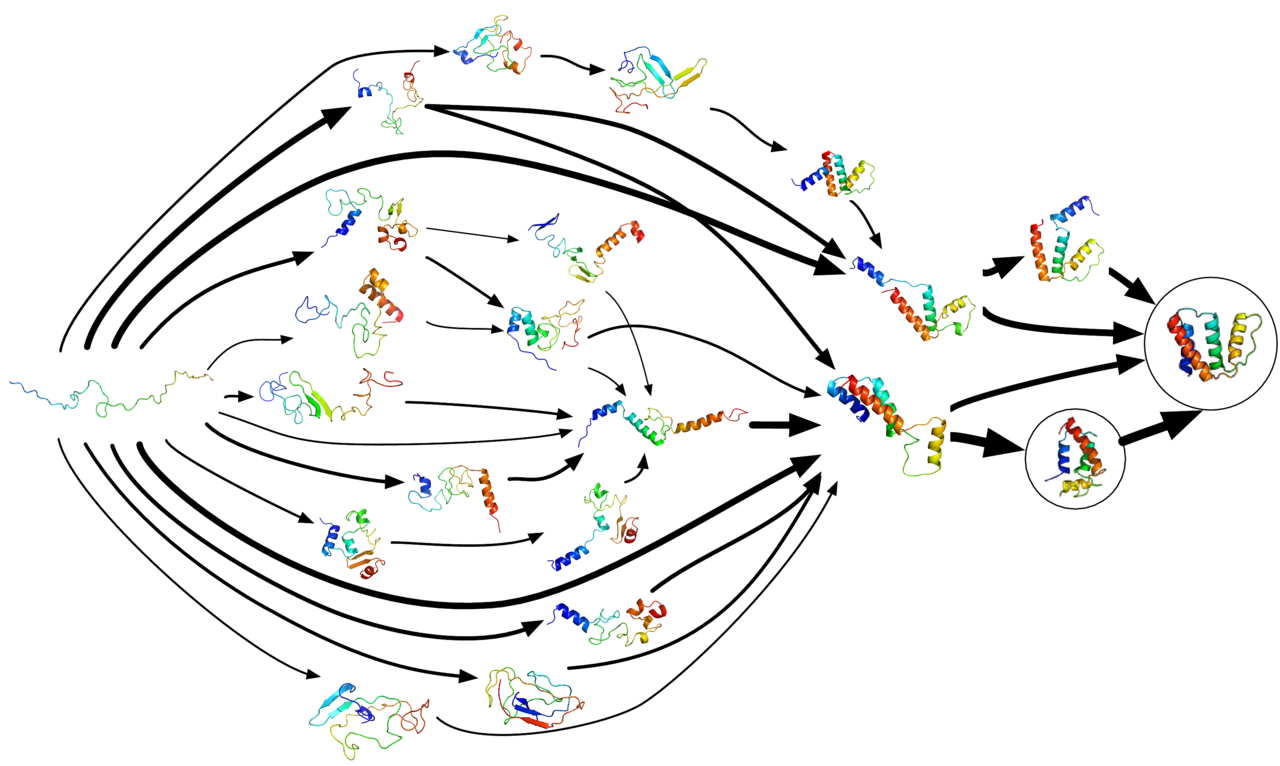
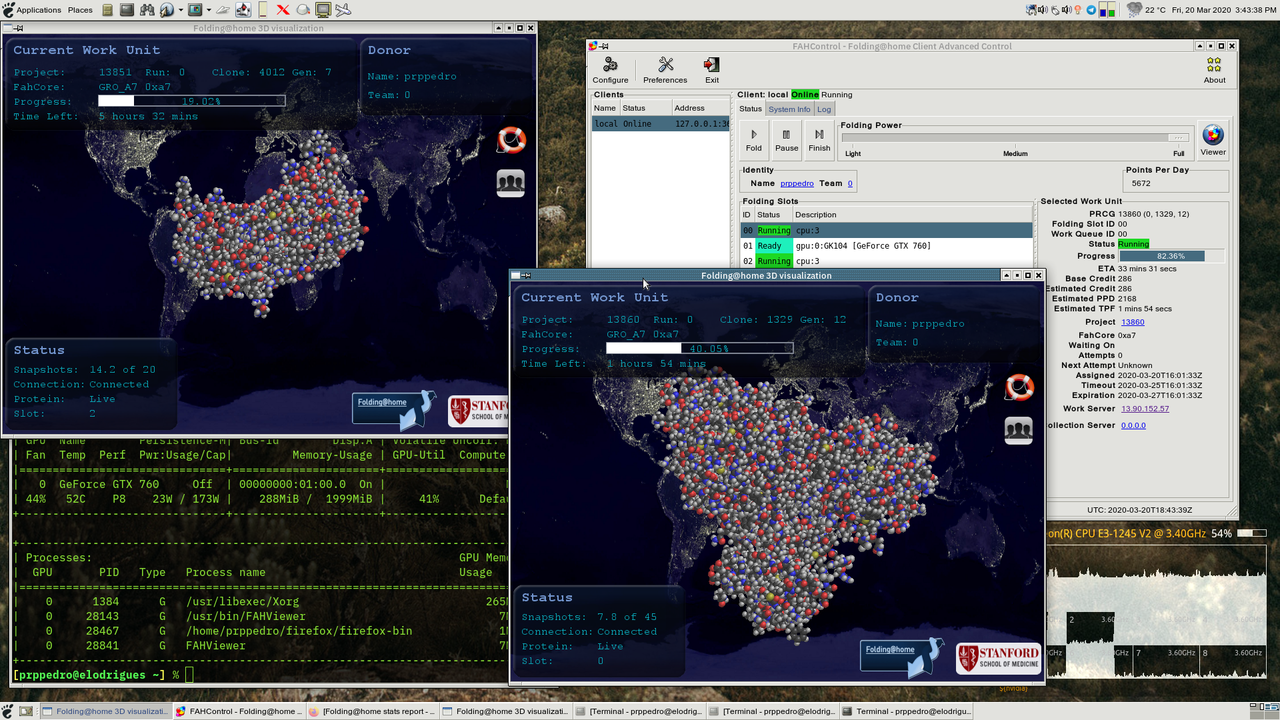



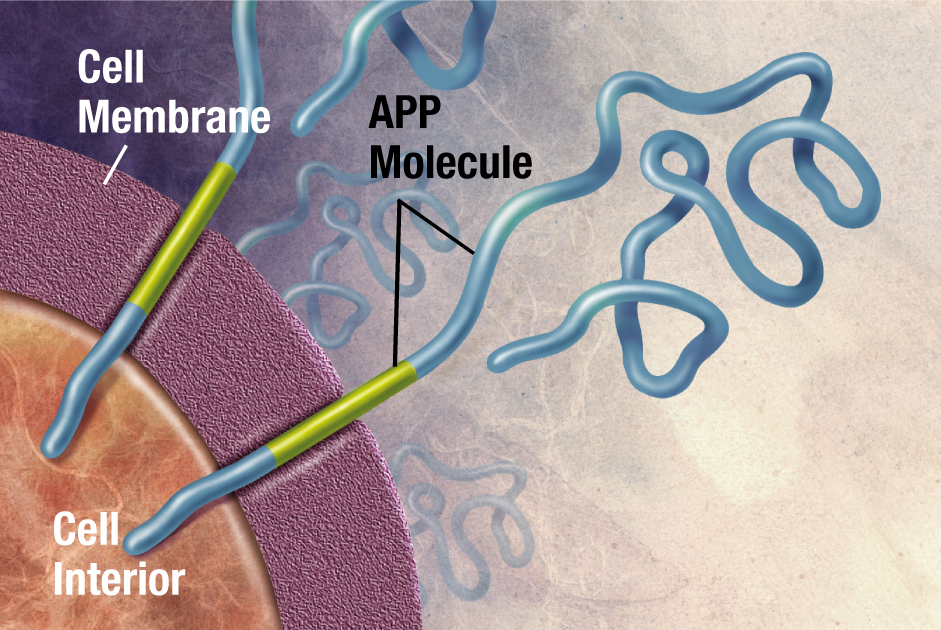


How it works
The project divides large problems into many independent "work units." A volunteer's machine—desktop CPU, GPU, or mobile device—receives a work unit, simulates molecular behavior for a period, and uploads computed data. The central servers collect results from many volunteers and combine them to build statistical models of protein dynamics. This distributed approach makes it possible to explore long-timescale behaviors that would otherwise require very expensive dedicated supercomputers.
Scientific focus and applications
Folding@home studies the physical process of protein folding and the failures that underlie conditions such as Alzheimer’s disease, prion diseases (for example, mad cow disease), and many cancers. By mapping pathways of folding and misfolding, researchers can identify transient structures and potential drug targets. Outputs from the project have supported academic publications and have been used in early-stage drug discovery, model building, and the development of computational methods for molecular biology.
History and development
The project began in the early 2000s as an academic initiative led by researchers interested in large-scale molecular simulation. Over time Folding@home evolved from a niche volunteer effort into one of the most recognized distributed research platforms. It has expanded client support across major operating systems and hardware types, and at times has mobilized rapidly during public health events to simulate proteins of urgent interest.
Participation, community and software
Anyone can participate by installing the project client and opting into one of several research projects or teams. The community aspect includes team competitions, contribution tracking, and forums where volunteers and researchers discuss results and software. The software design emphasizes fault tolerance and result validation so that work returned from diverse hardware can be aggregated reliably.
Strengths, limitations and notable facts
- Strengths: Low cost compared with dedicated supercomputers; access to a wide range of hardware that can speed up specific types of calculations.
- Limitations: Heterogeneous and intermittent resources require careful task design and validation; not all scientific problems split conveniently into independent work units.
- Notable: Folding@home has demonstrated how citizen science and volunteer computing can accelerate research and engage the public with real scientific questions.
Further reading and resources
For more information, installation instructions, or scientific publications related to the project, consult the official and community resources listed below:
- Project homepage
- How folding simulations work
- Academic lab information
- Research topics and disease focus
- Protein science background
- Neurodegenerative disease resources
- Prion disease information
- Cancer research context
- Volunteer client downloads
- Distributed computing concepts
- Historical platform support
- Console and alternative clients
- Browser and web interfaces
- Community forums and teams
- Mobile and Android clients
- Privacy, security and contribution policies
By combining volunteer computing with peer-reviewed science, Folding@home remains a prominent example of how distributed networks can contribute to long-term biomedical research.
Related articles
Author
AlegsaOnline.com Folding@home — distributed volunteer computing for protein research Leandro Alegsa
URL: https://en.alegsaonline.com/art/35359
Sources
- folding.stanford.edu : "What is protein folding?"
- techaeris.com : "Stanford's Research App Folding@Home Now Available On More Android Devices"