Isoform
A protein isoform is one of several distinct molecular forms produced from the same gene or related genes. Isoforms expand protein diversity by alternative splicing, allelic variation and post-translational changes.
A protein isoform is a distinct molecular variant of a protein that arises from the same gene or from closely related genes. Isoforms often differ in amino acid sequence, structure, cellular location or regulatory properties while retaining core functions. The term is widely used in molecular biology and proteomics to describe the natural diversity of protein forms that a genome can produce. For a concise definition and context see basic resources.
Image gallery
2 Images
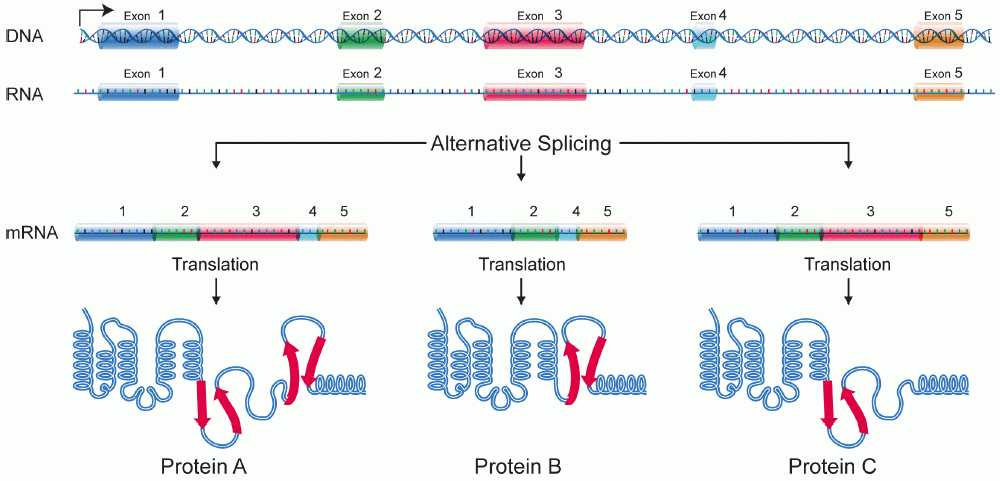
How isoforms are generated
Several biological mechanisms produce isoforms. Major routes include:
- Alternative splicing: A single pre-mRNA can be spliced in multiple ways to include or exclude exons, yielding proteins with different domains or lengths. See materials on RNA processing at RNA splicing references.
- Gene family and paralogues: Related genes arising from duplication can encode similar but distinct proteins that function as isoforms across tissues. Background on related genes is available at gene family resources.
- Allelic variation and SNPs: Single-nucleotide differences between alleles can change amino acids and create allele-specific isoforms; small variants are catalogued in genetic variation databases such as variation repositories.
- Alternative promoters/translation starts and proteolytic processing: Different transcription start sites or cleavage of a precursor protein produce forms with altered N- or C-termini.
- Post-translational modifications: Chemical modifications (phosphorylation, glycosylation, etc.) can generate functionally distinct proteoforms often discussed together with isoforms.
Functional importance and examples
Isoforms enable a single gene to serve multiple roles, permitting tissue-specific expression, developmental regulation, or rapid adaptation to cellular signals. For example, many signaling proteins and structural proteins exist in several isoforms that differ in regulatory sequences or binding partners. Changes in isoform expression are implicated in development and in diseases such as cancer, neurodegeneration and genetic disorders. Clinically, distinguishing isoforms can be critical because some drug targets or biomarkers are isoform-specific.
Detection, naming and practical distinctions
Researchers identify isoforms using RNA sequencing to infer splice variants, mass spectrometry to detect protein forms, and immunological assays when isoform-specific antibodies are available. Databases and protein resources commonly assign isoform identifiers (for example, "isoform 1", "isoform 2") to catalog variants; consult curated protein databases for standardized names via protein reference pages or gene-centric entries at sequence archives. The vocabulary can be imprecise: "isoform" is sometimes used interchangeably with "splice variant" or the broader term "proteoform," which emphasizes post-translational differences.
Understanding isoforms is essential for interpreting gene function, designing experiments, and developing therapies that target specific protein forms. For practical guidance on experimental approaches and data interpretation, see methodological overviews and reference materials such as splicing guides and variation resources at genetic databases.
Related articles
Author
AlegsaOnline.com Isoform Leandro Alegsa
URL: https://en.alegsaonline.com/art/48478