Supervised learning in machine learning: overview, methods, and applications
Supervised learning: a machine learning paradigm where models are trained on labeled examples to predict outcomes. Covers methods, history, evaluation, typical uses and differences from other learning types.
Overview
Supervised learning is a major branch of machine learning in which an algorithm learns a mapping from inputs to outputs using labeled examples. Each training example pairs an input (often represented as a vector of features) with a desired output or label. The goal is to produce a model that can predict the correct label for new, unseen inputs by generalizing from the training set rather than memorizing it.
Image gallery
2 Images
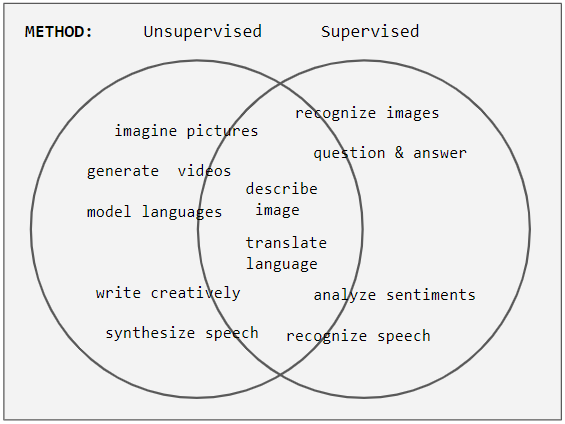
Basic characteristics
Key elements of supervised learning include training data, a model or hypothesis class, a loss function that measures prediction error, and an optimization procedure to minimize that loss. Inputs are commonly encoded as vectors or structured objects. Outputs may be continuous values (regression) or discrete categories (classification). During development practitioners split data into training, validation and test sets and apply techniques such as cross-validation to estimate performance.
Common algorithms
- Linear and logistic regression
- Decision trees and random forests
- Support vector machines
- k-nearest neighbors
- Neural networks and deep learning
History and principles
Supervised learning has roots in statistics and early pattern recognition research. Concepts such as linear regression and discriminant analysis predate modern computing; later developments—like the perceptron and kernel methods—expanded practical capacity. At a conceptual level supervised methods often rely on inductive reasoning: using observed labeled examples to infer a rule that will apply to new cases.
Applications and importance
Supervised learning powers many real-world systems: email spam filters, medical diagnosis tools, credit scoring, image and speech recognition, and recommendation engines. Its success depends on the availability and quality of labeled data, appropriate model choice, and careful evaluation to avoid overfitting.
Evaluation, limitations and distinctions
Performance is measured with metrics such as accuracy, precision, recall, mean squared error and ROC-AUC, depending on the task. Common challenges include noisy or biased labels, insufficient data, and overfitting; remedies include regularization, data augmentation and collecting more examples. Supervised learning is distinct from unsupervised learning (which finds structure without labels) and reinforcement learning (which learns from reward signals rather than explicit label pairs).
Further reading: introductory textbooks and surveys on supervised methods provide practical guidance on algorithm selection, model validation and deployment in production systems.
Related articles
Author
AlegsaOnline.com Supervised learning in machine learning: overview, methods, and applications Leandro Alegsa
URL: https://en.alegsaonline.com/art/95096