Evolutionary algorithm
Population-based optimization methods inspired by natural selection, using selection, recombination and mutation to evolve solutions for complex, multimodal, or discrete problems across science and engineering.
Evolutionary algorithms are a family of population-based optimization methods inspired by natural evolution. Used within computer science and artificial intelligence, they treat candidate solutions as individuals in a population and apply iterative operators to produce successive generations. A core idea is a fitness function that measures solution quality; better solutions are preferentially chosen to influence the next population. These methods are particularly useful when the search space is complex, discontinuous, noisy or lacks gradient information.
Image gallery
4 Images

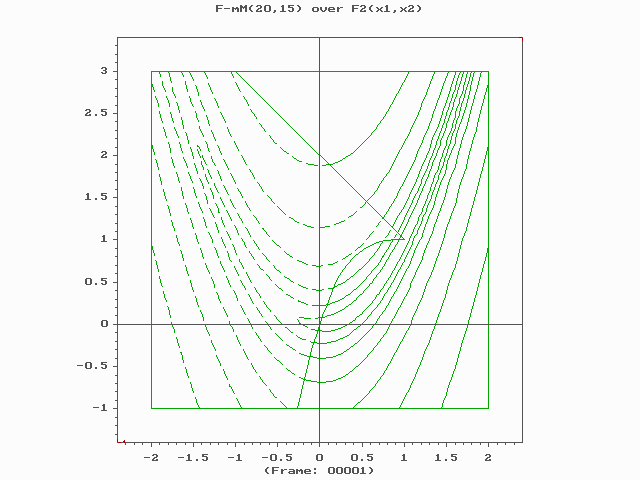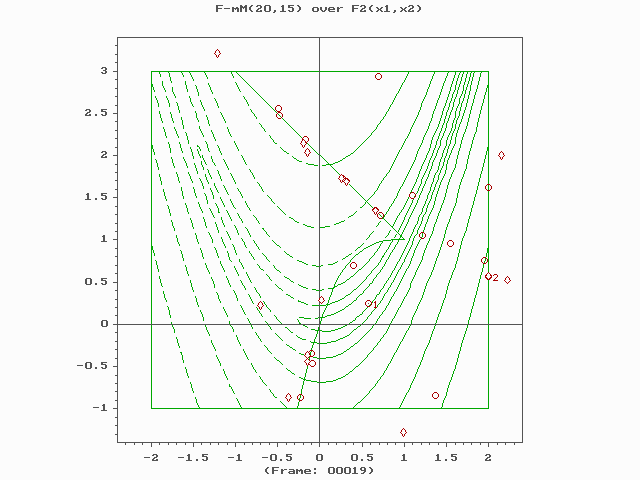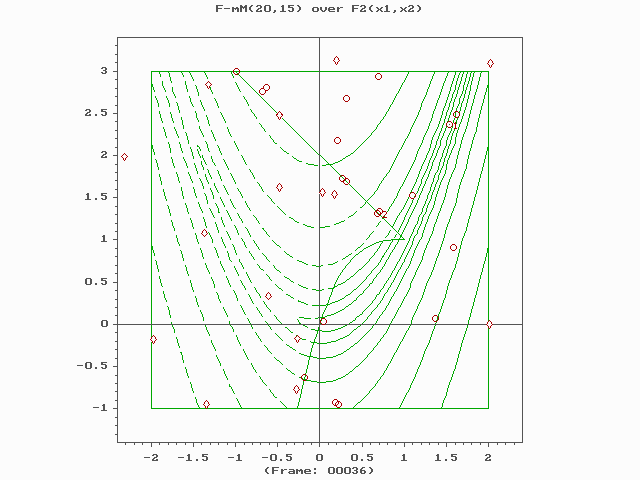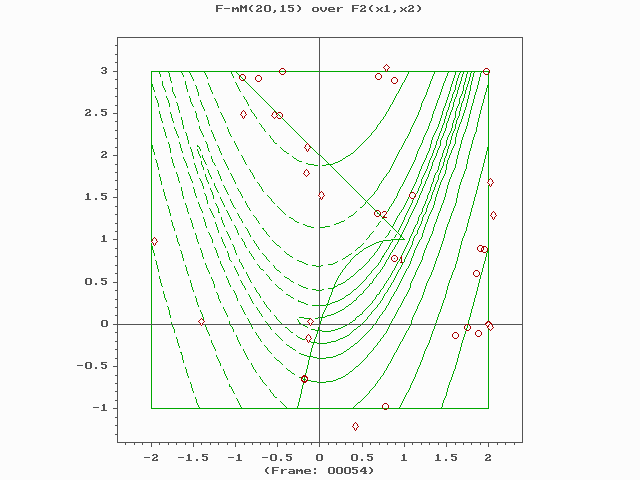

Core components and operators
An evolutionary algorithm typically implements several standard elements. A representation encodes candidate solutions (bit strings, real-valued vectors, tree structures, etc.). A fitness function evaluates each individual. Selection mechanisms choose which individuals contribute genetic material. Recombination (crossover) and mutation introduce variation. Finally, a replacement or survivor selection policy determines which individuals persist into the next generation. Together these components balance exploration of new regions and exploitation of promising solutions.
Variants and common types
- Genetic algorithms: use fixed-length representations and crossover/mutation operators for combinatorial or numerical problems.
- Evolution strategies: emphasize self-adaptive mutation rates and are often applied to continuous optimization.
- Genetic programming: evolves executable programs or expressions, typically represented as trees.
- Other hybrids: differential evolution and memetic algorithms combine evolutionary operators with problem-specific heuristics.
These variants differ in representation, operator design and selection pressure, but all share the population-based search and iterative improvement paradigm. The class of methods is sometimes collectively called evolutionary computation to emphasize this shared heritage.
History and development
Interest in biologically inspired search dates back to mid-20th-century work on cybernetics and adaptive systems. From the 1960s to 1980s researchers formalized approaches such as evolution strategies and genetic algorithms. Foundational studies provided theoretical and practical frameworks for encoding, variation, and selection. Over time the field incorporated ideas from population genetics, optimization theory and machine learning, producing tools that are now standard in engineering and research practice.
Applications and practical considerations
Evolutionary algorithms are applied to engineering design, scheduling, machine learning hyperparameter tuning, automatic program synthesis, art and procedural content generation, and bioinformatics, among others. They are valued for robustness, ease of parallelization and ability to handle mixed discrete-continuous variables. Typical drawbacks include computational cost, sensitivity to parameter settings (population size, mutation rate), and the risk of premature convergence to suboptimal solutions. Effective use requires careful choice of representation, operators and fitness shaping.
How they differ from other methods
Unlike gradient-based or exact solvers, evolutionary approaches do not require derivative information and can navigate rugged or discontinuous landscapes. They work with populations rather than a single candidate, which supports diverse search and multiple simultaneous trials. However, they offer no guaranteed global optimum; instead, they aim for good solutions within available time or resource limits. Implementations often combine evolutionary steps with local search, constraint handling, or surrogate models to improve efficiency.
For introductory material and algorithmic descriptions, see general references on algorithms and algorithm design that cover population-based search. To understand the biological analogy and models of selection used in the field, consult texts on natural evolution and computational simulation studies that simulate adaptive processes.
Related articles
Author
AlegsaOnline.com Evolutionary algorithm Leandro Alegsa
URL: https://en.alegsaonline.com/art/32837