Relational database: structure, theory, and practical uses
An overview of relational databases: definition, core concepts (tables, keys, joins, normalization), history, common uses, advantages, limitations, and how they differ from other data models.
Overview
A relational database is a method for storing and retrieving structured data using a tabular organization and well-defined relationships among records. In this model, information is arranged into tables made of rows (records) and columns (fields). Relationships between tables are expressed through keys and constraints, which let applications combine data from different tables in meaningful ways. The relational approach emphasizes a formal schema and declarative queries, making it easier to maintain data integrity and to reason about how data is connected.
Image gallery
2 Images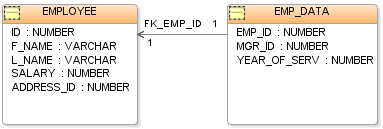
Core concepts and structure
At the heart of a relational database are a few foundational concepts:
- Tables (relations): Collections of rows sharing the same set of columns.
- Rows and columns: Rows represent individual records; columns represent attributes or fields.
- Primary key: A column or combination of columns that uniquely identifies each row in a table.
- Foreign key: A column that references the primary key of another table to express a relationship.
- Schema: The defined structure of tables, columns, types, and constraints that organizes the data model.
Relational databases support operations such as selection, projection, and joins, which are formalized in relational algebra. Query languages — most notably SQL — let users retrieve, insert, update, and delete data using readable, declarative statements.
History and development
The relational model was introduced as a formal approach to data management in the late 20th century and is commonly associated with Edgar F. Codd, who proposed the model as a mathematical alternative to earlier hierarchical and network data models. Implementations and commercial systems followed, and a distinct class of software—relational database management systems (RDBMS)—emerged to provide storage, query processing, concurrency control, and recovery. Over time, standards and extensions evolved, and SQL became the dominant language for interacting with relational systems.
Uses and examples
Relational databases are widely used across many industries for business applications that require consistency and structured queries. Typical domains include financial systems, customer relationship management, inventory and supply chain, healthcare records, and government registries. For example, a real-estate dataset might use one table for properties, another for transactions, and a third for buyers; foreign keys and joins let analysts group sales by year, buyer, or price range without duplicating data.
Advantages, integrity, and transactions
Key strengths of relational databases include strong data integrity through constraints and normalization, a mature ecosystem of tools, and support for complex queries. Transactional guarantees (often summarized as ACID properties) help ensure that concurrent operations leave data in a consistent state and that changes are durable and recoverable after failures. Normalization techniques reduce redundancy and update anomalies by organizing data into related tables according to rules that preserve dependencies.
Limitations and related approaches
Relational systems excel at structured, consistent data, but they can be less well suited to very large-scale, highly distributed, or schemaless datasets such as those used in some web-scale applications. Alternatives and complements—often grouped under “NoSQL” or non-relational technologies—favor flexible schemas, horizontal scaling, or specialized query patterns (document stores, key-value stores, wide-column stores, and graph databases). Choosing between a relational database and other models depends on requirements for consistency, transaction support, schema flexibility, and performance.
Further reading
To learn more about the formal model and practical implementations, see introductory materials on the relational model and general descriptions of a relational database. These resources explain theoretical foundations, common design patterns, and guidelines for normalization and indexing.
Related articles
Author
AlegsaOnline.com Relational database: structure, theory, and practical uses Leandro Alegsa
URL: https://en.alegsaonline.com/art/81999
Sources
- doi.org : 10.1145/362384.362685