Regression analysis: methods, assumptions, history, and common applications
Overview of regression analysis: concepts, main methods (linear, generalized, regularized), assumptions and diagnostics, history, typical uses, and common pitfalls in interpretation.
Overview
Regression analysis is a central topic in statistics concerned with describing, quantifying and predicting relationships between a dependent variable and one or more independent variables. At its core, regression fits a mathematical relationship to observed data to summarize patterns, forecast outcomes, estimate effects and test scientific ideas. The name covers a wide range of techniques, from simple straight-line fits to flexible, high-dimensional algorithms used in modern data science.
Image gallery
2 Images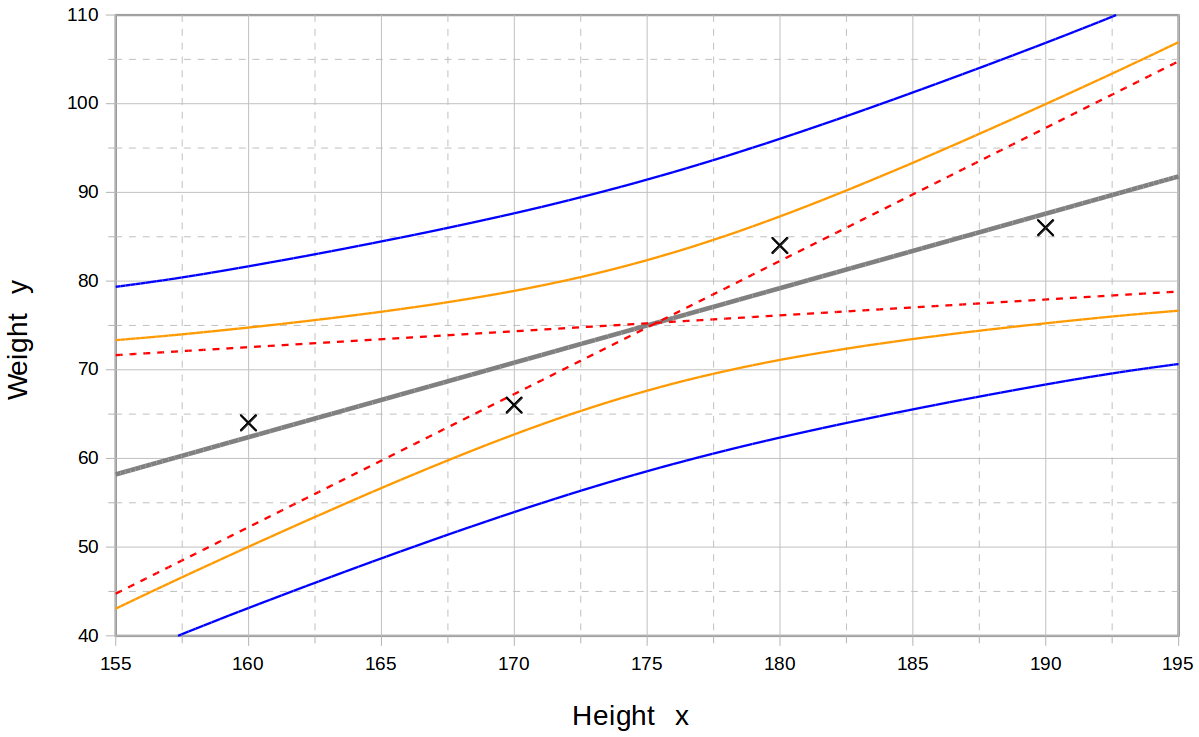
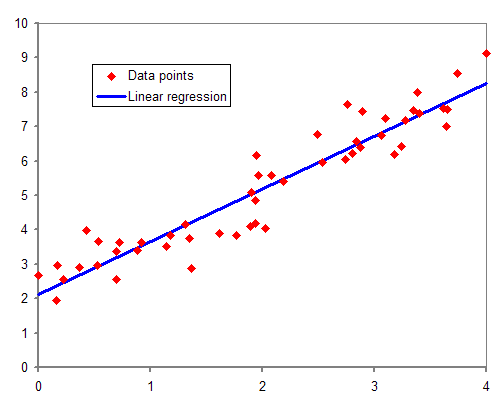
Key concepts
A regression model specifies a functional form that links inputs to outputs and a stochastic component that represents random variation or error. Important elements include parameters to be estimated, the distribution or behavior of residuals, measures of fit such as R-squared, and uncertainty quantification (confidence intervals, prediction intervals). Diagnostics typically examine residual patterns, leverage and influence to check whether the chosen form and assumptions are adequate.
Types and estimation methods
Common families of regression include linear regression for continuous outcomes, generalized linear models (which extend linear ideas to binary, count and other response types), logistic regression for binary responses, and survival models for time-to-event data. Nonlinear regression, polynomial and spline approaches model curved relationships, while nonparametric methods (kernels, local regression, trees) avoid a fixed parametric form.
Estimation can be performed by ordinary least squares, maximum likelihood, Bayesian inference or robust methods that downweight outliers. Regularization techniques such as ridge and lasso add penalty terms to control complexity and prevent overfitting in high-dimensional settings. Machine-learning implementations of regression emphasize predictive performance and often combine algorithmic models with cross-validation and resampling.
History and development
The method of least squares originated in early 19th-century work on astronomy and geodesy, with formal contributions by Legendre and Gauss providing the foundational calculational tools for fitting linear relations and predicting planetary motion. Since then, regression ideas have evolved to include generalized frameworks, robust estimators, multilevel models and computational algorithms for very large datasets.
Applications and examples
Regression is widely used for prediction, for statistical inference about relationships, and for formal hypothesis testing. Typical applications include forecasting economic indicators, estimating treatment effects in clinical studies, modeling risk factors in epidemiology, predicting customer demand in marketing, and calibrating engineering systems. Practical examples are predicting house prices from features, estimating how a medical exposure affects risk, or forecasting sales from seasonal and marketing inputs.
Assumptions, diagnostics and common pitfalls
Many regression methods rely on assumptions such as correct specification of the functional form, independence of error terms, constant variance (homoscedasticity), and often a particular error distribution for small-sample inference; these concern the underlying probability distribution of errors. Violations—such as omitted variables, multicollinearity, heteroscedasticity or correlated residuals—can bias estimates or invalidate standard errors and tests. Analysts routinely use residual plots, tests for heteroscedasticity, influence diagnostics and variance inflation factors to detect problems.
Model selection, validation and good practice
- Begin with simple, interpretable models and add complexity only when supported by diagnostics and theory.
- Use cross-validation and holdout samples to assess predictive performance and avoid overfitting; prefer out-of-sample evaluation for forecasting tasks.
- Apply regularization or variable-selection methods when dealing with many predictors, and compare models with information criteria or validation scores.
- Be cautious about interpreting associations as causal effects; causal claims usually require careful design, instrumental variables or randomized experiments.
- Recall that better numerical curve fits often require more complex procedures and careful model-checking; see discussions of curve fitting for trade-offs between fit and generalization.
Extensions and modern developments
Contemporary work extends regression to hierarchical and mixed-effects models for grouped data, generalized additive models for flexible smooth effects, penalized and sparse methods for high-dimensional inference, and combinations with machine-learning techniques. Time-series regression, quantile regression, and robust methods address specific data structures and violations of classical assumptions. Active research connects regression methods with causal inference frameworks and scalable computation.
Further resources
Introductory textbooks and methodological reviews provide step-by-step examples and code for estimation, diagnostics and validation. Applied software and documentation implement ordinary least squares, generalized linear models, regularization, and Bayesian approaches. For hands-on learning, consult statistical texts, online tutorials and domain-specific case studies that compare models and best practices in applied settings; these resources often cover core topics such as model-building, models, prediction, and formal inference and hypothesis testing.
Author
AlegsaOnline.com Regression analysis: methods, assumptions, history, and common applications Leandro Alegsa
URL: https://en.alegsaonline.com/art/81916
Sources
- links.jstor.org : links.jstor.org