Data Parallelism: concepts, patterns, and applications
Data parallelism distributes data across processors so the same operation runs concurrently on different elements; common in GPUs, databases and scientific computing, and distinct from task parallelism.
Overview
Data parallelism is a programming and execution strategy in which the same computational operation is applied simultaneously to many elements of a dataset. It is a central idea in parallel computing and is often described as "loop-level" parallelism because it arises naturally when the same loop body can be run on separate partitions of the data. The model contrasts with task parallelism, where different threads or processes perform different operations.
Image gallery
2 Images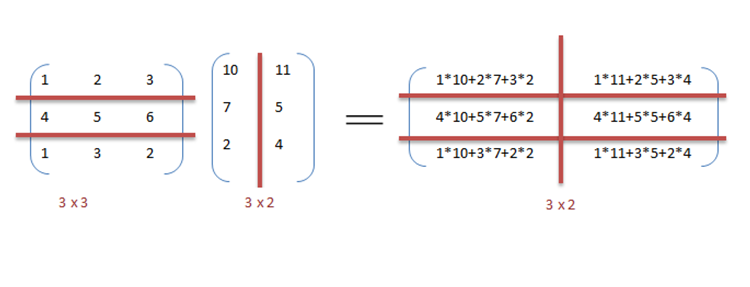
How it works
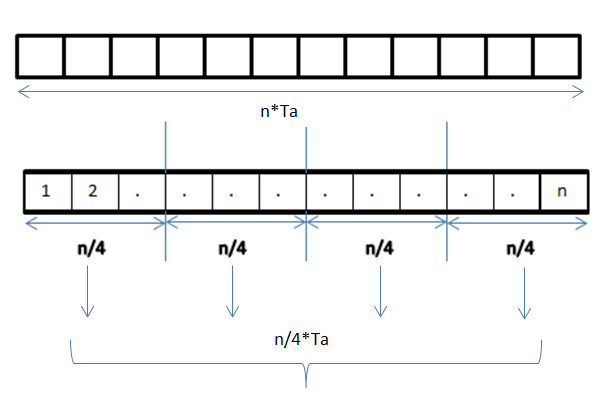
In a system with multiple processors or cores, data parallelism assigns disjoint subsets of a dataset to each processing element so each performs the same instruction sequence on its piece. Implementations vary: from single-instruction-multiple-data (SIMD) hardware and vector units to single-program-multiple-data (SPMD) software on clusters. The basic steps are partitioning data, executing the same code on each partition, and combining results when necessary. This technique relies on minimizing dependencies between partitions so work can proceed concurrently.
Characteristics and common patterns
- Uniform operations: Every worker executes the same algorithm, often on different array indices or records.
- Data partitioning: Strategies include block, cyclic, and hash-based splits to balance load and locality.
- Collective communication: When results must be merged, operations like reduction or scatter/gather are used, which introduce coordination overhead.
- Hardware mapping: Data parallelism maps well to vector units, GPUs, and distributed-memory clusters using frameworks such as OpenMP, CUDA, or message-passing systems.
History and development
The idea of applying the same operation across many data items grew with early vector processors and array machines, and it re-emerged with modern GPUs and multicore CPUs. Over time the pattern migrated from specialized hardware to widely used programming models and libraries that hide details of synchronization and communication. Researchers and engineers refined partitioning, scheduling, and memory access techniques to reduce overheads and exploit memory hierarchies.
Uses and examples
Data parallelism appears in many domains where large datasets are processed by a uniform computation. Typical examples include image and signal processing (pixels processed in parallel), linear algebra kernels (matrix and vector operations), machine learning training and inference (batch computations across examples), and analytics on database tables. Frameworks for big-data processing and scientific simulation often mix data parallel loops with task-level orchestration to meet complex requirements.
Advantages, limitations, and practical considerations
Advantages include straightforward scalability when work is evenly divisible, excellent utilization of SIMD/GPU hardware, and often simpler reasoning about correctness since each partition is mostly independent. Limitations arise from communication and synchronization costs, memory bandwidth contention, uneven partitioning that causes stragglers, and dependencies within data that prevent independent processing. Performance is commonly bounded by Amdahl-like trade-offs between parallel and sequential portions and by overheads that grow with the number of workers. Practical deployments measure and tune partition size, locality, and the balance between computation and communication to achieve good throughput.
For further conceptual and implementation guidance, see general resources on parallelization techniques, cluster and multiprocessor programming guides, and materials that explain effects on runtime and scalability.
Related articles
Author
AlegsaOnline.com Data Parallelism: concepts, patterns, and applications Leandro Alegsa
URL: https://en.alegsaonline.com/art/25637