Computer vision: principles, methods, and applications
An accessible overview of computer vision covering its goals, core tasks, principal methods (classical and deep learning), history, major applications, challenges, and emerging directions.
Computer vision is the area of computer science concerned with enabling machines to interpret and make decisions from visual data such as photographs, video, or depth maps. Rather than producing images (as in computer graphics), computer vision analyzes images to recognize objects, estimate geometry, follow motion, or extract semantic information. The field blends algorithms, statistical learning, and hardware considerations to convert raw pixels into useful descriptions of scenes and events.
Image gallery
7 Images




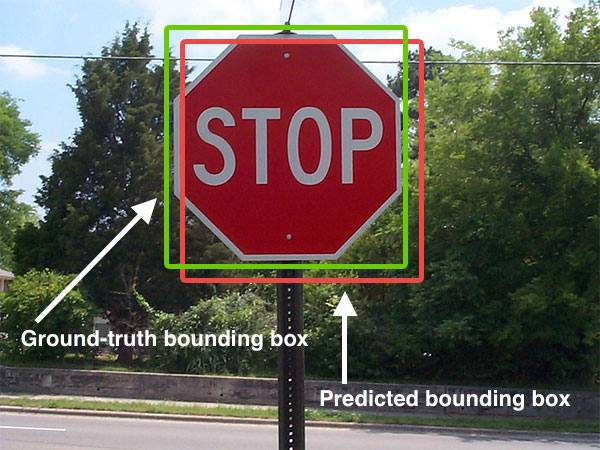

Core tasks and common outputs
- Image classification: assigning a label to an entire image (for example, identifying that a photo contains a cat).
- Object detection: locating and classifying multiple objects within an image, often with bounding boxes.
- Semantic and instance segmentation: labeling pixels by class or separating individual object instances.
- Pose and depth estimation: inferring 3D structure, camera position, or object orientation from images.
- Tracking and motion analysis: following objects across frames and computing optical flow.
These outputs can feed higher-level systems such as robotic control, visual search engines, or medical decision-support tools. Evaluation typically uses annotated datasets and performance metrics that vary by task (accuracy, IoU, recall/precision, tracking robustness).
Methods, tools, and development
Early computer vision relied on handcrafted features and geometric reasoning: edge detectors, gradient-based descriptors, the Hough transform for shapes, and stereo correspondence methods. Over the past decade, deep learning—especially convolutional neural networks (CNNs)—has become dominant for many tasks because of its ability to learn hierarchical features from large labeled datasets. Training and inference are also shaped by hardware choices: parallel processors such as GPUs and specialized accelerators enable large models and real-time processing.
Practical systems combine multiple modules (preprocessing, feature extraction, learning, post-processing) and increasingly integrate multimodal signals (audio, lidar, inertial sensors). Datasets and benchmark challenges have been central to progress, motivating improvements in model architecture, data augmentation, and evaluation protocols.
Applications, challenges, and outlook
- Applications: autonomous vehicles, medical imaging diagnosis, industrial inspection, robotics, augmented reality, surveillance, and remote sensing.
- Challenges: dataset bias, domain shift, interpretability, robustness to occlusion and adversarial input, and privacy concerns when applied to people.
- Outlook: research is moving toward more efficient models for edge devices, better unsupervised and self-supervised learning to reduce labeling needs, and tighter integration with other sensing modalities and symbolic reasoning.
For developers and researchers seeking introductory materials or community resources, see further reading and tutorials that survey foundational concepts, representative algorithms, and contemporary toolkits.
Related articles
Author
AlegsaOnline.com Computer vision: principles, methods, and applications Leandro Alegsa
URL: https://en.alegsaonline.com/art/22337