Plain text (unformatted textual data)
Plain text is human-readable characters without embedded formatting commands; it relies on character encodings and simple conventions and is widely used for files, code, and data exchange.
Overview
Plain text refers to sequences of readable characters stored or transmitted without embedded formatting instructions. It contains letters, digits, punctuation and control characters, but not styling, fonts or layout metadata. Because it encodes content as simple characters, plain text is portable across many programs and platforms and is often the baseline representation for human-readable data.
Image gallery
1 Image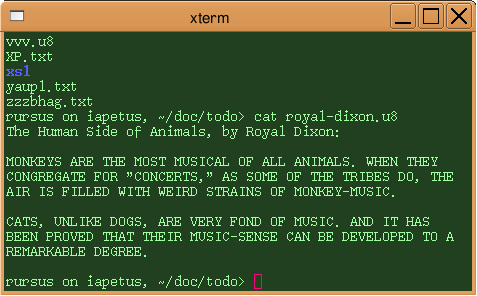
Characteristics
Key features of plain text include:
- Human-readable: Content can be read with simple editors and displayed on terminals.
- Encoding-dependent: The meaning of bytes depends on a character encoding such as ASCII or Unicode; see character encoding for related concepts.
- No formatting: It lacks style information like bold, colors or embedded layout commands.
- Simple structure: Lines, whitespace and basic control characters are used to separate content.
History and development
Plain text emerged with early computing and telecommunication systems that exchanged characters over limited channels. Early standards such as ASCII established common numeric codes for basic characters; larger, multi-byte encodings later expanded support for global scripts. The simplicity of plain text made it a natural choice for configuration files, email, and source code in the formative decades of computing.
Uses and examples
Plain text is used for many everyday tasks: source code, configuration and log files, simple documents, email messages (raw form), and data interchange formats like CSV or simple tab-delimited files. Typical file extensions include .txt, .csv and many script or markup files. A plain text file can be opened with basic editors; see a typical plain text file workflow in many systems.
Distinctions and notable facts
Plain text contrasts with rich text and binary formats that embed formatting or non-textual data. While extremely portable, plain text depends on agreement about character encoding and line-ending conventions. It is easier to diff, search and version-control than formatted documents, which helps developers and data professionals. For international text, Unicode encodings are commonly used to represent a wide range of scripts while preserving the plain-text principle.
Related articles
Author
AlegsaOnline.com Plain text (unformatted textual data) Leandro Alegsa
URL: https://en.alegsaonline.com/art/77213
Sources
- webopedia.com : "What is plain text? Webopedia Definition"