Genetic code: how nucleotide sequences specify proteins
The genetic code is the set of rules by which nucleotide triplets (codons) in DNA or mRNA specify amino acids during protein synthesis. It is largely universal, degenerate, and central to molecular biology.
The genetic code is the set of molecular rules that translate information encoded in nucleic acids into the amino acid sequences of proteins. In cells, the sequence of nucleotides in DNA or in the messenger RNA derived from it is read three bases at a time to form codons; each codon corresponds to a specific amino acid or a translation signal. The decoding machinery is based on the ribosome, which coordinates transfer RNAs and links amino acids into a growing polypeptide chain. The same basic language appears across nearly all organisms, which is why the genetic code is central to genetics and biotechnology.
Image gallery
3 Images
Mechanics and defining features
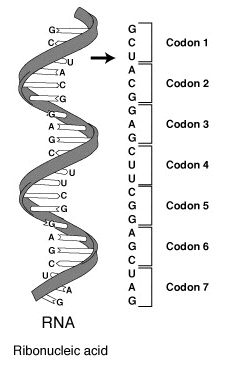
The basic unit of the code is the codon, a triplet of nucleotides that is read in a defined reading frame. There are 64 possible codons (4^3) and 20 standard amino acids, so most amino acids are encoded by more than one codon, a property called degeneracy. A typical gene's coding region in the genome is transcribed to mRNA and then translated by the ribosome; this process begins at a start codon and ends at one of three stop codons that signal termination. Transfer RNA molecules match codons to their amino acids via complementary anticodons and, through wobble at the third base, allow flexibility that reduces the number of distinct tRNAs required.
History of discovery
Decoding the genetic code was a major achievement of mid-20th-century molecular biology. Experiments combining synthetic RNA templates and cell-free translation systems revealed which codons specify which amino acids and showed the triplet nature of the code. These laboratory milestones connected the abstract sequence information found in encoded DNA with the chemical reality of proteins and established how a gene determines protein sequence.
Importance and practical uses
Understanding the genetic code enables genetic engineering, recombinant protein production, and many diagnostic tools. Codon choice influences translation efficiency and protein folding, so scientists perform codon optimization in heterologous expression systems. Mutations that change codons can be silent, missense, nonsense, or cause frameshifts, affecting when and where proteins are produced and their function; regulatory regions control when and where genes are expressed.
Variations, limits and notable facts
- Although nearly universal, several well-documented variants exist (for example in mitochondrial genomes) that reassign particular codons.
- The code's redundancy provides some protection against point mutations, while frameshift errors can have more severe effects.
- Studies of code evolution explore why particular assignments arose and how the code balances robustness and adaptability.
Because the code ties sequence to function, it remains a foundational concept in biology and a practical tool in medicine, biotechnology and synthetic biology. Research continues into nonstandard amino acids, engineered codes, and how changes to the code might be used to create new biological functions.
See also: DNA, proteins, amino acids, nucleotides, and resources on translation at encoded information and cell machinery described in ribosome-focused reviews. For broader context consult materials on genomics and genes in the genome and specific gene-level discussions at gene-oriented references. Additional educational links: translation, comparative biology, and applied topics such as expression timing covered under when and where.



History of the discovery
In the first half of the 1960s, there was some competition among biochemists to understand the genetic code. On May 27, 1961, at 3 a.m., German biochemist Heinrich Matthaei made a decisive breakthrough in Marshall Nirenberg's laboratory with the Poly-U experiment: the decoding of codon UUU for the amino acid phenylalanine. This experiment is considered by some geneticists to be the most significant of the 20th century. In 1966, five years after the decoding of the first codon, the complete decoding of the genetic code with all 64 base triplets had been achieved.
Codon
Genetic information for the assembly of proteins is contained in specific sections of the base sequence of nucleic acids. Transcribed from DNA into RNA, it becomes available for the biosynthesis of proteins. The base sequence present in the open reading frame is read at the ribosome and translated (translated) according to the genetic code into the amino acid sequence of the synthesized peptide chain, the primary structure of a protein. In this process, the base sequence is read step by step in groups of three and each triplet is assigned a matching tRNA loaded with a specific amino acid. Each amino acid is bound to the previous one by peptide binding. In this way, the sequence segment codes for protein.
A codon is the variation pattern of a sequence of three nucleobases of the mRNA, a base triplet that can code for an amino acid. A total of 43 = 64 possible codons exist, 61 of which code for the total of 20 canonical proteinogenic amino acids; the remaining three are so-called stop codons for the termination of translation. Under certain circumstances, these can be used to encode two additional non-canonical amino acids. Thus, there are several different codings for almost all of the amino acids, each usually quite similar. However, coding as a triplet is necessary insofar as duplet coding would result in only 42 = 16 possible codons, which would already leave insufficient possibilities for the twenty canonical or standard amino acids.
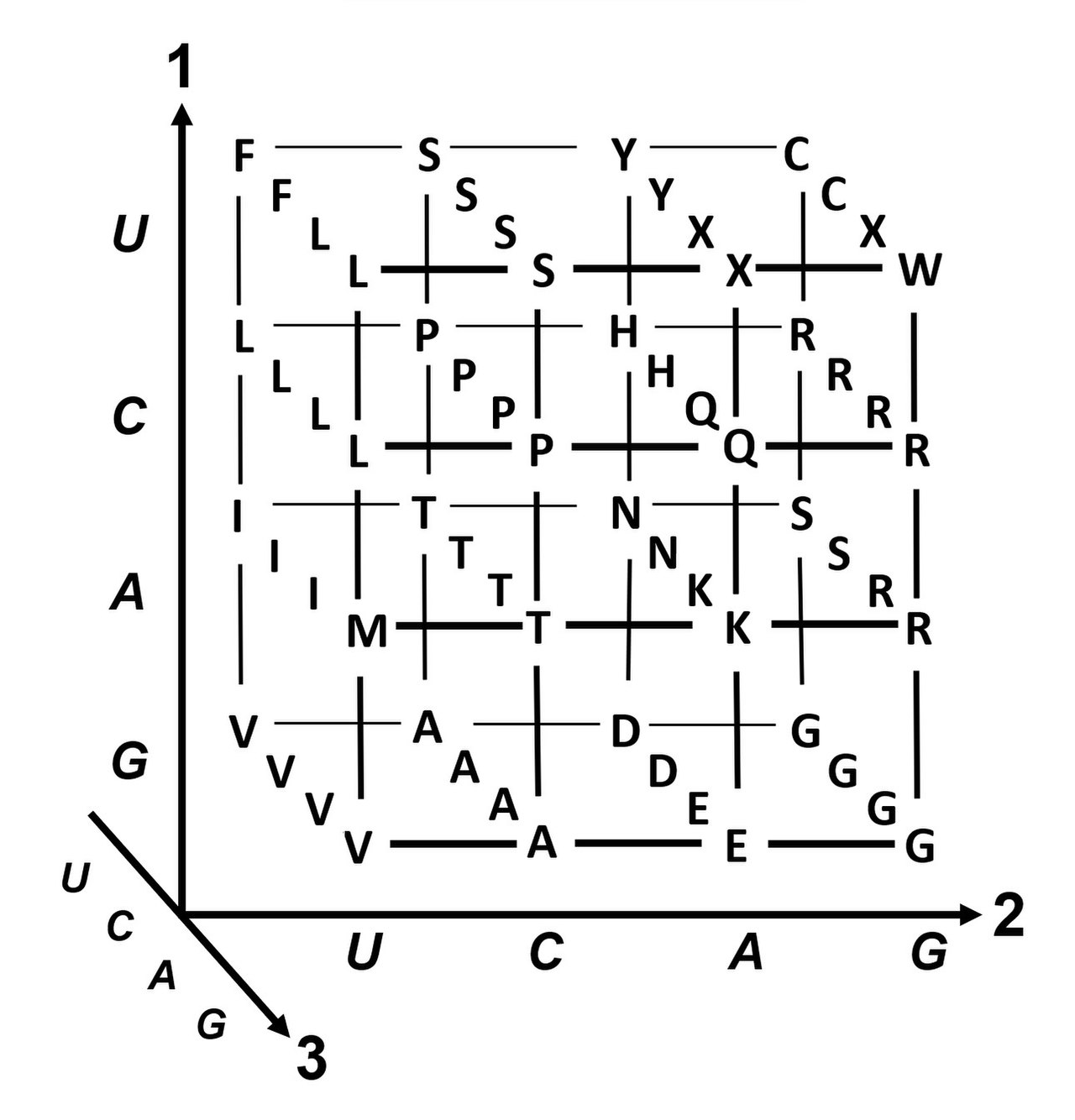
| Standard codon table for all 64 possible base triplets | ||||||||||||||||||||||||||||||||||||||
| 2. base |
| |||||||||||||||||||||||||||||||||||||
| U | C | A | G |
| ||||||||||||||||||||||||||||||||||
| 1. base | U |
|
|
|
|
| ||||||||||||||||||||||||||||||||
| C |
|
|
|
|
| |||||||||||||||||||||||||||||||||
| A |
|
|
|
|
| |||||||||||||||||||||||||||||||||
| G |
|
|
|
|
| |||||||||||||||||||||||||||||||||
| Coloring of the amino acids hydrophobic (non-polar) hydrophilic neutral (polar) hydrophilic and positively charged (basic) hydrophilic and negatively charged (acidic) | * The triplet of the codonAUGfor methionine also serves as a translation start signal. One of the first AUG triplets on the mRNA becomes the first codon to be decoded. The ribosome recognizes which AUG is to be used as the start codon for the tRNAiMet by signals from the neighboring mRNA sequence. The |
| ||||||||||||||||||||||||||||||||||||
The codons indicated apply to the nucleotide sequence of an mRNA. It is read in the 5′→3′ direction on the ribosome and translated into the amino acid sequence of a polypeptide.
| Reverse codon table | |||
| Az | AS | AS | Codon |
| 1 | Start | > | AUG |
| 1 | Met | M | AUG |
| 1 | W | UGG | |
| 1 | U | (UGA) | |
| 1 | Pyl | O | (UAG) |
| 2 | Y | UAU UAC | |
| 2 | Phe | F | UUU UUC |
| 2 | C | UGU UGC | |
| 2 | Asn | N | AAU AAC |
| 2 | Asp | D | GAU GAC |
| 2 | Gln | Q | CAA CAG |
| 2 | E | GAA GAG | |
| 2 | His | H | CAU CAC |
| 2 | Lys | K | AAA AAG |
| 3 | Ile | I | AUU AUC AUA |
| 4 | Gly | G | GGU GGC GGA GGG |
| 4 | A | GCU GCC GCA GCG | |
| 4 | Val | V | GUU GUC GUA GUG |
| 4 | Thr | T | ACU ACC ACA ACG |
| 4 | Per | P | CCU CCC CCA CCG |
| 6 | Leu | L | CUU CUC CUA CUG UUA UUG |
| 6 | Ser | S | UCU UCC UCA UCG AGU AGC |
| 6 | Arg | R | CGU CGC CGA CGG AGA AGG |
| 3 | < | UAA UAG UGA | |
Translation begins with a start codon. However, certain initiation sequences and factors are also necessary to cause the binding of the mRNA to a ribosome and to start the process. This includes a special initiator tRNA that carries the first amino acid. The most important start codon is AUG, which codes for methionine. ACG and CUG - as well as GUG and UUG in prokaryotic cells - can also serve as start codons, but with lower efficiency. However, the first amino acid is mostly a methionine - N-fomylated in bacteria and in mitochondria.
The translation ends with one of the three stop codons, also called termination codons. Initially, these codons were also given names - UAG is amber, UGA is opal, and UAA is ochre (a pun on the last name of their discoverer Harris Bernstein).
While the codon UGA is mostly read as stop, it can rarely and only under certain conditions stand for a 21st (proteinogenic) amino acid: Selenocysteine (Sec). The biosynthesis and insertion mechanism of selenocysteine into proteins is very different from that of all other amino acids: its insertion requires a novel translation step in which a UGA is interpreted differently in the context of a specific sequence environment and together with specific cofactors. This also requires a structurally unique tRNA (tRNASec) specific for selenocysteine, which in vertebrates can also be loaded with two chemically related amino acids: serine or phosphoserine in addition to selenocysteine.
In addition, some archaea and bacteria can translate a canonical stop codon UAG into another (22nd) proteinogenic amino acid: Pyrrolysine (Pyl). They have a special tRNAPyl as well as a specific enzyme to load it (pyrrolysyl-tRNA synthetase).
Some short DNA sequences occur only rarely or not at all in the genome of a species (nullomers). In bacteria, some of these prove to be toxic; the codon AGA, which codes for the amino acid arginine, is also avoided in bacteria (CGA is used instead). There are definitely species-specific differences in codon usage. Differences in codon usage do not necessarily mean differences in the abundance of amino acids used. This is because there is more than a single codon for most of the amino acids, as the table above shows.
Degeneration and fault tolerance
If a certain amino acid is to be encoded, it is often possible to choose among several codons with the same meaning. The genetic code is a code in which several expressions have the same meaning, i.e. the same semantic unit can be encoded by different syntactic symbols. Compared to a coding system in which one syntactic expression corresponds to each semantic unit and vice versa, such a code is called degenerate.
It has the advantage that more than 60 codons are available for the approximately 20 amino acids to be translationally inserted. They are represented as a combination of three nucleotides with four possible bases each, so that there are 64 combinations. Their respective assignment to an amino acid is such that very similar codon variations code for a specific amino acid. Due to the error tolerance of the genetic code, two nucleotides are often sufficient to specify an amino acid with certainty.
The base triplets coding for an amino acid usually differ in only one of the three bases; they have the minimum distance in code space, see Hamming distance or Levenshtein distance. Mostly, triplets differ in the third base, the "wobbling" one, which is most likely to be misread during translations (see "wobble" hypothesis). Amino acids frequently needed for protein assembly are represented by more codons than those rarely used. A deeper analysis of the genetic code reveals further correlations, for example with regard to the molar volume and the hydrophobic effect (see figure).
It is also noteworthy that the base in the middle of a triplet can largely indicate the character of the assigned amino acid: Thus, in the case of _ U _ they are hydrophobic, but hydrophilic in the case of _ A _. In the case of _ C _ they are nonpolar or polar without charge, those with charged side chains occur in _ G _ as well as in _ A _, with negative charge only in _ A _ (see table above). Therefore, radical substitutions - the exchange for amino acids of a different character - are often a consequence of mutations in that second position. Mutations in the third position ("wobble"), on the other hand, often preserve the respective amino acid or at least its character as a conservative substitution. Since transitions (conversion of purines or pyrimidines into each other, for example C→T) occur more frequently than transversions (conversion of a purine into a pyrimidine or vice versa; this process usually requires depurination) for mechanistic reasons, a further explanation for the conservative properties of the code emerges.
Contrary to earlier assumptions, the first codon position is often more important than the second position, presumably because changes in the first position alone can reverse the charge (from a positively charged to a negatively charged amino acid or vice versa). Charge reversal, however, can have dramatic consequences for protein function. This was overlooked in many previous studies.
The so-called degeneracy of genetic codes also makes it possible to store genetic information less sensitive to external influences. This is particularly true with regard to point mutations, both synonymous mutations (leading to the same amino acid) and non-synonymous mutations leading to amino acids with similar properties.
Apparently, early in evolutionary history, it was helpful to lower the susceptibility of coding to incorrectly formed codons. The function of a protein is determined by its structure. This depends on the primary structure, the sequence of amino acids: how many, which ones and in which order are linked to form a peptide chain. The base sequence contains this information as genetic information. An increased error tolerance of the coding ensures correct decoding. If an amino acid of a similar character is inserted in the case of an incorrect one, this changes the protein function less than if it were of a completely different character.

Origin of the genetic code
The use of the word "code" goes back to Erwin Schrödinger, who had used the terms "hereditary code-script", "chromosome code" and "miniature code" in a series of lectures in 1943, which he summarized in 1944 and used as the basis for his 1944 book "What is Life?". The exact location or carrier of this code was still unclear at that time.
In the past, it was believed that the genetic code arose by chance. As late as 1968, Francis Crick referred to it as "frozen chance". However, it is the result of strict optimization with regard to error tolerance. Errors are particularly serious for the spatial structure of a protein if the hydrophobicity of an incorrectly incorporated amino acid differs significantly from the original. In a statistical analysis, among a million random codes, only 100 turn out to be better than the actual one in this respect. If additional factors corresponding to typical patterns of mutations and reading errors are taken into account when calculating the error tolerance, this number is even reduced to 1 in 1 million.
Code universality
Basic principle
It is remarkable that the genetic code is in principle the same for all living beings, i.e. all living beings use the same "genetic language". Not only is genetic information present in all of them in the sequence of nucleic acids, and is always read in triplets for the construction of proteins. With a few exceptions, a specific codon also stands for the same amino acid in each case; the standard code reflects the common usage. This is why it is possible in genetic engineering, for example, to insert the gene for human insulin into bacteria so that they then produce the hormone protein insulin. This basic principle of coding, shared by all organisms, is called "universality of code." It is explained by evolution in such a way that the genetic code was shaped very early in the evolutionary history of life and then passed on by all evolving species. Such generalization does not exclude the possibility that the frequency of different code words may differ between organisms (see Codon Usage).
Variants
In addition, there are also various variants that deviate from the standard code, i.e. in which a few codons are translated into an amino acid other than that specified in the #standard codon table. Some of these deviations can be narrowed down taxonomically, so that special codes can be defined. In this way, more than thirty variant genetic codes have already been distinguished.
In eukaryotic cells, those organelles that have an independent genomic system and are presumably derived from symbiotic bacteria (endosymbiont theory) show their own variants of the genetic code. In mitochondria, more than ten modified forms of mitochondrial code are known for their own DNA (mtDNA, mitogenome syn. chondriome). These differ from the nuclear code for the genetic material in the nucleus, the nuclear genome (karyome). In addition, the plastids that also occur in plant cells have their own code for their plastid DNA (cpDNA, plastome).
The ciliates (Ciliophora) also show deviations from the standard code: UAG, not infrequently also UAA, code for glutamine; this deviation is also found in some green algae. UGA also sometimes stands for cysteine. Another variant is found in the yeast Candida, where CUG codes for serine.
Furthermore, there are some variants of amino acids that can be incorporated by recoding not only by bacteria (Bacteria) and archaea (Archaea) during translation; for example, as described above, UGA can encode selenocysteine and UAG can encode pyrrolysine, in the standard code of both stop codons.
In addition, other deviations from the standard code are known, which often concern initiation (start) or termination (stop); especially in mitochondria, a codon (base triplet of the mRNA) is often not assigned the usual amino acid. Some examples are listed in the following table:
| Deviations from the standard code | |||
| Occurrence | Codon | Standard | Deviation |
| Mitochondria (in all organisms examined so far) | UGA | Stop | Tryptophan |
| Mammalian, Drosophila and S. cerevisiae and protozoan mitochondria. | AUA | Isoleucine | Methionine = Start |
| Mammalian mitochondria | AGC, AGU | Serine | Stop |
| Mammalian mitochondria | AG(A, G) | Arginine | Stop |
| Mitochondria from Drosophila | AGA | Arginine | Stop |
| Mitochondria e.g. in Saccharomyces cerevisiae | CU(U, C, A, G) | Leucine | Threonine |
| Mitochondria of higher plants | CGG | Arginine | Tryptophan |
| Some species of the fungal genus Candida | CUG | Leucine | Serine |
| Eukarya (rare) | CUG | Leucine | Start |
| Eukarya (rare) | ACG | Threonine | Start |
| Eukarya (rare) | GUG | Valine | Start |
| Bacteria | GUG | Valine | Start |
| Bacteria (rare) | UUG | Leucine | Start |
| Bacteria (SR1 Bacteria) | UGA | Stop | Glycine |
Genetic codes in DNA alphabet
DNA sequence databases such as GenBank also report mRNA sequences in a format that conforms to historical conventions, using the DNA alphabet, i.e., T instead of U. Examples:
- Standard code (= id)
- Vertebrate Mitochondrial Code
- Yeast Mitochondrial Code
- Invertebrates Mitochondrial Code
Note: In the respective first line "AS", the amino acids are indicated in the one-letter code (see #Inverted Codon Table), with deviations from the standard code (id) shown in bold (or red) in each case. In the second line "Starts" M shows Initiation, * Termination; some variants differ solely with respect to (alternative) start codons or stop codons. Further codes can be taken from the freely accessible source.
Engineering of the genetic code
→ Main article: Synthetic biology
Generally, the concept of evolution of the genetic code from the original and ambiguous original genetic code to the well-defined ("frozen") code with the repertoire of 20 (+2) canonical amino acids is accepted. However, there are different opinions and ideas on how these changes took place. Based on these, models are even proposed that predict "entry points" for the invasion of the genetic code with synthetic amino acids.
See also
- Codogenic strand
- Epigenetic code
- Gene duplication
- Xenobiology
Related articles
Author
AlegsaOnline.com Genetic code: how nucleotide sequences specify proteins Leandro Alegsa
URL: https://en.alegsaonline.com/art/37990
Sources
- ncbi.nlm.nih.gov : "Genetic code supports targeted insertion of two amino acids by one codon"
- doi.org : 10.1126/science.1164748
- pubmed.ncbi.nlm.nih.gov : 19131629
- doi.org : 10.1016/j.gene.2008.11.001
- pubmed.ncbi.nlm.nih.gov : 19056476