Differential calculus: rates of change, derivatives, and applications
Differential calculus studies instantaneous rates of change and tangent behavior of functions. It defines derivatives, basic computation rules, higher derivatives, multivariable extensions, and common applications.
Differential calculus is the branch of mathematical analysis concerned with how quantities change in relation to one another. It formalizes the notion of instantaneous rate of change through the derivative and gives a geometric interpretation as the slope of the tangent line to a curve. For general context, see calculus; for the idea of a dependent quantity use variable; and many models are expressed by a function.
Image gallery
5 Images




Core concepts
The primary object is the derivative. Informally, the derivative of y = f(x) at x=a measures how much y changes per small change in x near a. A common formulation is as a limiting ratio: the derivative is the limit of the difference quotient as the increment approaches zero. A function with a derivative at a point is called differentiable there; differentiability implies continuity, but a continuous function need not be differentiable.
- Difference quotient: (f(x+h)-f(x))/h, h→0.
- Limit process: taking the limit of the difference quotient defines the derivative.
- Basic rules: linearity, product rule, quotient rule, and chain rule simplify calculations.
Notation and higher derivatives
Common notations include f'(x), dy/dx, Df(x) and higher-order derivatives such as f''(x) or d2y/dx2. Higher derivatives describe rates of change of rates of change: for example, acceleration is the second derivative of position with respect to time. The existence and continuity of higher derivatives are central to Taylor series and many approximation methods.
Multivariable extensions
When functions depend on several variables, partial derivatives measure change with respect to one variable while holding others fixed. The gradient is a vector of first partial derivatives and points in the direction of steepest increase. The Jacobian matrix generalizes the derivative for vector-valued functions, and the Hessian matrix collects second partial derivatives to analyze curvature and extrema in multiple dimensions.
Techniques for finding derivatives
Routine computation uses derivative rules and known derivatives of elementary functions. Additional techniques include implicit differentiation for relations not given as explicit functions, logarithmic differentiation for products and powers, and differentiation under the integral sign in certain advanced contexts. When analytic forms are difficult or unavailable, numerical differentiation approximates derivatives from sampled data.
Practical applications
Derivatives appear across science, engineering, and economics. In physics, velocity and acceleration are first and second derivatives of position with respect to time. In optimization, setting derivatives (or gradients) to zero locates candidate maxima and minima; second-derivative tests help classify them. In engineering and control theory, derivatives are used to model rates, sensitivities and linear approximations. In economics, marginal concepts are derivatives of cost, revenue or utility functions.
Historical notes and further study
The development of differential calculus in the late 17th century involved independent contributions by Sir Isaac Newton and Gottfried Wilhelm Leibniz. Newton applied rate-of-change ideas to motion and physical problems; Leibniz developed much of the symbolic notation still used today. See short biographies at Sir Isaac Newton and Gottfried Leibniz. Modern study moves from single-variable theory to multivariable analysis, differential equations and numerical methods, and connects tightly with integral calculus via the fundamental theorem that links differentiation and integration.

Introduction
Introduction by means of an example
If a car is driving on a road, this fact can be used to create a table in which the distance covered since the start of the recording is entered at each point in time. In practice, it is useful not to keep such a table too close-meshed, i.e., for example, to make a new entry only every 3 seconds in a period of 1 minute, which would require only 20 measurements. However, such a table can theoretically be made arbitrarily close-meshed, if every point in time is to be taken into account. In this case, the previously discrete data, i.e. data with a distance, merge into a continuum. The present is then interpreted as a point in time, i.e. as an infinitely short period of time. At the same time, however, the car has covered a theoretically measurable exact distance at every point in time, and if it does not slow down to a standstill or even reverse, the distance will increase continuously, i.e. it will never be the same at any point in time as at another.
· 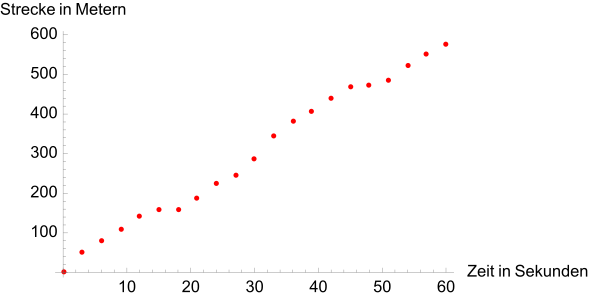
Exemplary representation of a table, every 3 seconds a new measurement is entered. Under such conditions, only average velocities can be calculated in the periods 0 to 3, 3 to 6 etc. seconds can be calculated. Since the distance covered always increases, the car seems to move only forward.
· 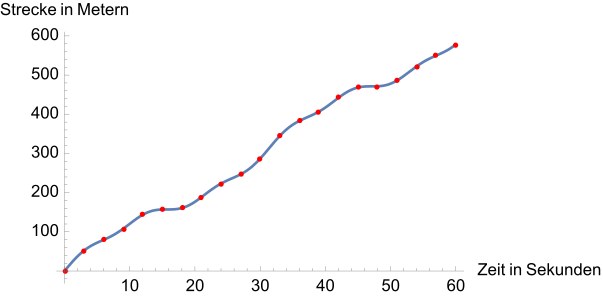
Potential transition to an arbitrarily close-meshed table, which takes the form of a curve after all points have been entered. Now a distance
is assigned to each time point between 0 and 60 seconds. Regions, within which the curve runs more steeply upwards, correspond to time periods, in which a larger number of meters per time unit is covered. In regions with an almost constant number of meters, for example in the range 15-20 seconds, the car drives slowly and the curve runs flat.
The motivation behind the notion of deriving a time-distance table or function is to now be able to specify how fast the car is moving at a certain present time. From a time-stretch table the appropriate time-speed table is to be derived. The background is that speed is a measure of how much the distance traveled changes over time. If the speed is high, a strong increase in the distance can be seen, while a low speed leads to little change. Since each time point has also been assigned a distance, such an analysis should in principle be possible, because with the knowledge of the distance traveled  within a time period
within a time period  the following applies to the velocity
the following applies to the velocity

Thus, if  and
and  two different times, "the speed" of the car in the period between them is
two different times, "the speed" of the car in the period between them is

The differences in numerator and denominator have to be formed, since one is only interested in the distance 
 traveled within a certain time period Nevertheless, this approach does not provide a complete picture, since initially only velocities for "real time periods" were measured. A present velocity, comparable to a speed camera photo, on the other hand, would refer to an infinitely short time interval. Furthermore, it is very possible that the car still changes its speed even in very short intervals, for example during emergency braking. Accordingly, the upper term "speed" is not applicable and must be replaced by "average speed". Thus, if real time intervals, i.e. discrete data, are used, the model is simplified in that a constant speed is assumed for the car within the intervals considered.
traveled within a certain time period Nevertheless, this approach does not provide a complete picture, since initially only velocities for "real time periods" were measured. A present velocity, comparable to a speed camera photo, on the other hand, would refer to an infinitely short time interval. Furthermore, it is very possible that the car still changes its speed even in very short intervals, for example during emergency braking. Accordingly, the upper term "speed" is not applicable and must be replaced by "average speed". Thus, if real time intervals, i.e. discrete data, are used, the model is simplified in that a constant speed is assumed for the car within the intervals considered.
If, on the other hand, we want to move on to a "perfectly fitting" time-velocity table, the term "average velocity in a time interval" must be replaced by "velocity at a point in time". To do this, a time must first be chosen. The idea now is to run "real time intervals" in a limit process against an infinitely short time interval and study what happens to the average velocities involved. Although the denominator to 0, this is not a problem, because the car can move less and less far in shorter time intervals with a continuous course, i.e. without teleportation, so that numerator and denominator decrease at the same time, and in the limit process an indefinite term "  " arises. This can make sense as a limit value under certain circumstances, for example, express
" arises. This can make sense as a limit value under certain circumstances, for example, express

exactly the same velocities. Now there are two possibilities when studying the velocities. Either, they do not show any tendency to approach a certain finite value in the considered limit process. In this case, no velocity valid at time can be assigned to the motion of the car, i.e., the term " " has no definite meaning here. If, on the other hand, there is an increasing stabilization in the direction of a fixed value, then there exists the limit

and expresses exactly the prevailing speed of the car at time The indeterminate term " " takes on a unique value in this case. The resulting numerical value is also called the derivative of at location and the symbol often  used for it.
used for it.
The principle of differential calculus
The example of the last section is particularly simple if the increase of the distance of the car with time is uniform, i.e. linear. In this case, one also speaks of a proportionality between time and distance, if at the beginning of the recording (  ) no distance has been covered yet (
) no distance has been covered yet (  ). This results in an always constant change of the distance in a certain time interval, no matter from when the measurement starts. For example, between 0 and 1 the car covers the same distance as between 9 and 10 seconds. If we assume that the car moves 2 meters further for every second that elapses, proportionality means that it moves only 1 meter for every half second, and so on. In general, then,
). This results in an always constant change of the distance in a certain time interval, no matter from when the measurement starts. For example, between 0 and 1 the car covers the same distance as between 9 and 10 seconds. If we assume that the car moves 2 meters further for every second that elapses, proportionality means that it moves only 1 meter for every half second, and so on. In general, then,  i.e., for each additional unit of time, two additional units of distance are added, so that the rate of change at each point is 2 "meters per (added) second".
i.e., for each additional unit of time, two additional units of distance are added, so that the rate of change at each point is 2 "meters per (added) second".
For the more general case, replacing 2 by any number  , i.e.
, i.e.  , then for each elapsed time unit, another distance units are added. This can be seen quickly, because the following applies to the distance difference
, then for each elapsed time unit, another distance units are added. This can be seen quickly, because the following applies to the distance difference

In general, the car moves forward in time units by a total of  distance units - its speed is therefore, in case of the choice of meters and seconds made, constant " meters per second". If the starting value is not but
distance units - its speed is therefore, in case of the choice of meters and seconds made, constant " meters per second". If the starting value is not but  , this does not change anything, since the constant in the upper difference always subtracts out. This is also reasonable from an illustrative point of view: The starting position of the car should be irrelevant for its speed if the motion is uniform.
, this does not change anything, since the constant in the upper difference always subtracts out. This is also reasonable from an illustrative point of view: The starting position of the car should be irrelevant for its speed if the motion is uniform.
It can therefore be stated:
- Linear functions. For linear functions (note that it does not have to be an origin line), the derivative term is explained as follows. If the function under consideration has the form
 then the instantaneous rate of change at each point has the value , so it is true for the corresponding derivative function
then the instantaneous rate of change at each point has the value , so it is true for the corresponding derivative function  . Thus, the derivative can be read directly from the data
. Thus, the derivative can be read directly from the data  In particular, every constant function
In particular, every constant function  has the derivative
has the derivative  , since changing the input values does not change the output value. The measure of change is therefore 0 everywhere.
, since changing the input values does not change the output value. The measure of change is therefore 0 everywhere.
Sometimes it can be much more difficult if a movement is not uniform. In this case, the course of the time-stretch function may look completely different from a straight line. From the nature of the time-stretch function, it can then be seen that the car's motion trajectories are very varied, which may have to do with traffic lights, curves, traffic jams and other road users, for example. Since such types of progressions are particularly common in practice, it is convenient to extend the derivation notion to non-linear functions as well. Here, however, one quickly encounters the problem that, at first glance, there is no clear proportionality factor that precisely expresses the local rate of change. Therefore, the only possible strategy is to linearize the nonlinear function to reduce the problem to the simple case of a linear function. This technique of linearization forms the very calculus of differential calculus and is of very great importance in calculus, since it helps to reduce complicated processes locally to very easily understood processes, namely linear processes.
The strategy can be exemplified by the non-linear function  The following table shows the linearization of the quadratic function at position 1.
The following table shows the linearization of the quadratic function at position 1.
|
| 0,5 | 0,75 | 0,99 | 0,999 | 1 | 1,001 | 1,01 | 1,1 | 2 | 3 | 4 | 100 |
|
| 0,25 | 0,5625 | 0,9801 | 0,998001 | 1 | 1,002001 | 1,0201 | 1,21 | 4 | 9 | 16 | 10000 |
|
| 0 | 0,5 | 0,98 | 0,998 | 1 | 1,002 | 1,02 | 1,2 | 3 | 5 | 7 | 199 |

That the linearization is only a local phenomenon is shown by the increasing deviation of the function values at more distant input values. The linear function  mimics the behavior of near input 1 very well (better than any other linear function). However, unlike for one has an easy time interpreting the rate of change at the point 1: It is (as everywhere) exactly 2. Thus
mimics the behavior of near input 1 very well (better than any other linear function). However, unlike for one has an easy time interpreting the rate of change at the point 1: It is (as everywhere) exactly 2. Thus  .
.
It can therefore be stated:
- Non-linear functions. If the instantaneous rate of change of a non-linear function is to be determined at a certain point, it must be linearized there (if possible). Then the slope of the approximate linear function is the local rate of change of the non-linear function under consideration, and the same view applies as for derivatives of linear functions. In particular, the rates of change of a non-linear function are not constant, but will change from point to point.
The exact determination of the correct linearization of a non-linear function at a given point is the central task of the calculus of differential calculus. The question is whether it is possible to calculate from a curve such as which linear function it best approximates at a given point. Ideally, this calculation is even so general that it can be applied to all points in the domain of definition. In the case of can be shown that at the point  the best linear approximation must have
the best linear approximation must have slope With the additional information that the linear function
slope With the additional information that the linear function  must intersect the curve at the point the full functional equation of the approximating linear function can then be obtained. In many cases, however, the specification of the slope, i.e. the derivative, is sufficient.
must intersect the curve at the point the full functional equation of the approximating linear function can then be obtained. In many cases, however, the specification of the slope, i.e. the derivative, is sufficient.
The starting point is the explicit determination of the limit value of the differential quotient

from which for very small h by simple transformation the expression

emerges. The right-hand side is a function linear in with slope
in with slope  and mimics
and mimics 
 very well near For some elementary functions such as polynomial functions, trigonometric functions, exponential functions, or logarithmic functions, a derivative function can be determined by this limit process. With the help of so-called derivation rules, this process can then be generalized to many other functions, such as sums, products or concatenations of elementary functions like those mentioned above.
very well near For some elementary functions such as polynomial functions, trigonometric functions, exponential functions, or logarithmic functions, a derivative function can be determined by this limit process. With the help of so-called derivation rules, this process can then be generalized to many other functions, such as sums, products or concatenations of elementary functions like those mentioned above.
Exemplary: If and  , then the product is
, then the product is  approximated by the product of the linear functions:
approximated by the product of the linear functions:  , and by multiplying out:
, and by multiplying out:

where the gradient of  at
at  corresponds
corresponds  exactly to Furthermore, the derivation rules help to replace the sometimes time-consuming limit determinations by a "direct calculus" and thus simplify the derivation process. For this reason, differential quotients are studied in teaching for fundamental understanding and are used to prove the derivation rules, but are not applied in computational practice.
exactly to Furthermore, the derivation rules help to replace the sometimes time-consuming limit determinations by a "direct calculus" and thus simplify the derivation process. For this reason, differential quotients are studied in teaching for fundamental understanding and are used to prove the derivation rules, but are not applied in computational practice.
Exemplary calculation of the derivative
The approach to the derivative calculation is first the difference quotient. This can be demonstrated by the functions and 
In the case of the binomial formula 
 helps. This gives
helps. This gives

In the last step the term was absorbed in the difference and a factor shortened. If now tends to 0,  only remains in the limit from the "secant slope" 2
only remains in the limit from the "secant slope" 2  - this is the sought exact tangent slope
- this is the sought exact tangent slope  . In general, for polynomial functions, derivation decreases the degree by one.
. In general, for polynomial functions, derivation decreases the degree by one.
Another important type of function is exponential functions, such as . Here, for each input factors 10 are multiplied together, for example  ,
,  or
or  . This can also be generalized to non-integer numbers by means of "splitting" factors into roots (e.g.,
. This can also be generalized to non-integer numbers by means of "splitting" factors into roots (e.g.,  ). Exponential functions, the characteristic equation is
). Exponential functions, the characteristic equation is

which is based on the principle that the product of factors 10 and  factors 10 consists of
factors 10 consists of  factors 10. In particular, there exists a direct connection between any differences
factors 10. In particular, there exists a direct connection between any differences  and
and  through
through

This triggers the important (and for exponential functions peculiar) effect that the derivative function must correspond to the derived function except for one factor:

The factor, except for which function and derivative are equal, is the derivative at the point 0. Strictly speaking, it must be verified that this exists at all. If so, is  already derivable everywhere.
already derivable everywhere.
The calculation rules are described in detail in the section Derivation Calculation.
Classification of the application possibilities
Extreme value problems
→ Main article: Extreme value problem
An important application of the differential calculus is that the derivative can be used to determine local extreme values of a curve. So instead of having to search mechanically for high or low points using a table of values, the calculus provides a direct answer in some cases. If there is a high or low point, the curve has no "real" slope at this point, which is why the optimal linearization has a slope of 0. For the exact classification of an extreme value, however, further local data of the curve are necessary, because a slope of 0 is not sufficient for the existence of an extreme value (let alone a high or low point).
In practice, extreme value problems typically occur when processes, for example in the economy, are to be optimized. Often there are unfavorable results at the marginal values, but in the direction of the "middle" there is a steady increase, which then has to be maximized somewhere. For example, the optimal choice of a sales price: If the price is too low, the demand for a product is very high, but the production cannot be financed. On the other hand, if it is too high, in extreme cases it will not be bought at all. Therefore, an optimum lies somewhere "in the middle". The prerequisite for this is that the relationship can be represented in the form of a (continuously) differentiable function.
The examination of a function for extreme points is part of a curve discussion. The mathematical background is provided in the section Application of higher derivatives.
Mathematical modeling
In mathematical modeling, complex problems are to be captured and analyzed in mathematical language. Depending on the problem, the investigation of correlations or causalities or also the giving of prognoses are target-oriented within the framework of this model.
Especially in the environment of so-called differential equations, the differential calculus is a central tool for modeling. These equations occur, for example, when there is a causal relationship between the stock of a quantity and its change over time. An everyday example could be:
The more inhabitants a city has, the more people want to move there.
More concretely, this could mean, for example, that with  current residents, an average of people will move in over the next 10 years, and with
current residents, an average of people will move in over the next 10 years, and with  inhabitants on average persons in the next 10 years, etc.-so as not to have to run all the numbers individually: If
inhabitants on average persons in the next 10 years, etc.-so as not to have to run all the numbers individually: If  people live in the city, so many people want to move in that another would be added after 10 years. If there is such a causality between stock and change over time, it can be asked whether a forecast for the number of inhabitants after 10 years can be derived from these data if, for example, the city had inhabitants in 2020. In doing so, it would be wrong to believe that this will be
people live in the city, so many people want to move in that another would be added after 10 years. If there is such a causality between stock and change over time, it can be asked whether a forecast for the number of inhabitants after 10 years can be derived from these data if, for example, the city had inhabitants in 2020. In doing so, it would be wrong to believe that this will be  since as the population increases, the demand for housing will in turn increasingly increase. The crux of understanding the correlation is thus once again its locality: if the city has inhabitants, then at this point people want to move in per 10 years. But a short moment later, when more people have moved in, the situation looks different again. If this phenomenon is thought to be arbitrarily close-meshed in time, a "differential" correlation results. However, in many cases the continuous approach is also suitable for discrete problems.
since as the population increases, the demand for housing will in turn increasingly increase. The crux of understanding the correlation is thus once again its locality: if the city has inhabitants, then at this point people want to move in per 10 years. But a short moment later, when more people have moved in, the situation looks different again. If this phenomenon is thought to be arbitrarily close-meshed in time, a "differential" correlation results. However, in many cases the continuous approach is also suitable for discrete problems.
With the help of differential calculus, a model can be derived from such a causal relationship between stock and change in many cases, which resolves the complex relationship in the sense that a stock function can be explicitly specified at the end. If, for example, the value 10 years is then inserted into this function, the result is a forecast for the number of city residents in 2030. In the case of the upper model, a stock function  sought with
sought with  , in 10 years, and
, in 10 years, and  . The solution is then
. The solution is then

with the natural exponential function (natural means that the proportionality factor between stock and change is simply equal to 1), and for 2030 the estimated forecast is  million population. Thus, the proportionality between population and rate of change leads to exponential growth and is a classic example of a self-reinforcing effect. Analogous models work for population growth (the more individuals, the more births) or for the spread of a contagious disease (the more diseased, the more contagions). In many cases, however, these models reach a limit when natural constraints (such as an upper limit on the total population) prevent the process from continuing indefinitely. In these cases, similar models, such as logistic growth, are more appropriate.
million population. Thus, the proportionality between population and rate of change leads to exponential growth and is a classic example of a self-reinforcing effect. Analogous models work for population growth (the more individuals, the more births) or for the spread of a contagious disease (the more diseased, the more contagions). In many cases, however, these models reach a limit when natural constraints (such as an upper limit on the total population) prevent the process from continuing indefinitely. In these cases, similar models, such as logistic growth, are more appropriate.
Numerical methods
The property of a function to be differentiable is advantageous in many applications, since this gives the function more structure. One example is solving equations. In some mathematical applications, it is necessary to find the value of one (or more) unknown , which is the zero of a function It is then  . Depending on the nature of strategies can be developed to specify a zero at least approximately, which is usually quite sufficient in practice. If is differentiable at every point with derivative
. Depending on the nature of strategies can be developed to specify a zero at least approximately, which is usually quite sufficient in practice. If is differentiable at every point with derivative  then Newton's method can help in many cases. In this method, the differential calculus plays a direct role insofar as a derivative must always be calculated explicitly in the stepwise procedure.
then Newton's method can help in many cases. In this method, the differential calculus plays a direct role insofar as a derivative must always be calculated explicitly in the stepwise procedure.
Another advantage of differential calculus is that in many cases complicated functions, such as roots or even sine and cosine, can be well approximated using simple calculation rules such as addition and multiplication. If the function is easy to evaluate at an adjacent value, this is of great benefit. For example, if an approximation for the number  sought, the differential calculus for
sought, the differential calculus for  the linearization
the linearization

because it is proved that  . Both function and first derivative could be calculated well
. Both function and first derivative could be calculated well at the point because it is a square number. Inserting
at the point because it is a square number. Inserting  gives
gives  , which
, which  agrees with the exact result
agrees with the exact result  within an error less than By including higher derivatives, the accuracy of such approximations can be additionally increased, since then not only linear, but quadratic, cubic, etc. is approximated, see also Taylor series.
within an error less than By including higher derivatives, the accuracy of such approximations can be additionally increased, since then not only linear, but quadratic, cubic, etc. is approximated, see also Taylor series.
Pure mathematics
Differential calculus also plays an important role in pure mathematics as a core of calculus. An example is differential geometry, which deals with figures that have a differentiable surface (without kinks, etc.). For example, a plane can be placed tangentially on a spherical surface at any point. Illustratively, if you stand at a point on the earth, you will have the feeling that the earth is flat if you let your gaze wander in the tangential plane. In reality, however, the earth is only locally flat: The applied plane serves the simplified representation (by linearization) of the more complicated curvature. Globally it has a completely different shape as a spherical surface.
The methods of differential geometry are extremely important for theoretical physics. Thus, phenomena such as curvature or spacetime can be described by methods of differential calculus. Also the question, what is the shortest distance between two points on a curved surface (for example the earth's surface), can be formulated and often answered with these techniques.
Differential calculus has also proved its worth in the study of numbers as such, i.e. within the framework of number theory, in analytic number theory. The basic idea of analytic number theory is to transform certain numbers about which one wants to learn something into functions. If these functions have "good properties" such as differentiability, one hopes to be able to draw conclusions about the original numbers via the structures that accompany them. It has often proven useful to move from real to complex numbers in order to perfect analysis (see also complex analysis), i.e. to study functions over a larger range of numbers. An example is the analysis of the Fibonacci numbers  , whose law of formation dictates that a new number should always arise from the sum of the two preceding ones. Approach of the analytic number theory is the formation of the generating function
, whose law of formation dictates that a new number should always arise from the sum of the two preceding ones. Approach of the analytic number theory is the formation of the generating function

i.e. of an "infinitely long" polynomial (a so-called power series) whose coefficients are exactly the Fibonacci numbers. For sufficiently small numbers this expression makes sense, because the powers  then go towards 0 much faster than the Fibonacci numbers go towards infinity, so in the long run everything settles down at a finite value. It is possible for these values to calculate the function
then go towards 0 much faster than the Fibonacci numbers go towards infinity, so in the long run everything settles down at a finite value. It is possible for these values to calculate the function  explicitly by
explicitly by

The denominator polynomial  "mirrors" exactly the behavior
"mirrors" exactly the behavior  of the Fibonaccinumbers f_{n}}
of the Fibonaccinumbers f_{n}} fact
fact  by termwise arithmetic. On the other hand, differential calculus can be used to show that the function sufficient to uniquely characterize the Fibonacci numbers (their coefficients). However, since it is a plain rational function, this allows us to find the exact formula valid for any Fibonacci number
by termwise arithmetic. On the other hand, differential calculus can be used to show that the function sufficient to uniquely characterize the Fibonacci numbers (their coefficients). However, since it is a plain rational function, this allows us to find the exact formula valid for any Fibonacci number

with the golden ratio  when
when  and
and  set. The exact formula is able to calculate a Fibonacci number without knowing the previous ones. The conclusion is drawn by a so-called coefficient comparison and uses that the polynomial
set. The exact formula is able to calculate a Fibonacci number without knowing the previous ones. The conclusion is drawn by a so-called coefficient comparison and uses that the polynomial  has
has  as zeros
as zeros  and
and
The higher dimensional case
The differential calculus can be generalized to the case of "higher dimensional functions". This means that both input and output values of the function are not merely part of the one-dimensional real number ray, but also points of a higher-dimensional space. An example is the rule

between two-dimensional spaces in each case. The function understanding as a table remains identical here, only that this has "clearly more" entries with "four columns"  Multidimensional mappings can also be linearized at a point in some cases. However, it is now appropriate to note that there can be multiple input dimensions as well as multiple output dimensions: The correct way to generalize is that the linearization in each component of the output accounts for each variable in a linear fashion. This draws for upper example function an approximation of the form
Multidimensional mappings can also be linearized at a point in some cases. However, it is now appropriate to note that there can be multiple input dimensions as well as multiple output dimensions: The correct way to generalize is that the linearization in each component of the output accounts for each variable in a linear fashion. This draws for upper example function an approximation of the form

after itself. This then mimics the entire function  very well near the input Accordingly, in each component, a "slope" is given for each variable - this will then measure the local behavior of the component function for small change in that variable. This slope is also called the partial derivative. The correct constant intercepts
very well near the input Accordingly, in each component, a "slope" is given for each variable - this will then measure the local behavior of the component function for small change in that variable. This slope is also called the partial derivative. The correct constant intercepts  calculated exemplarily by
calculated exemplarily by  or
or  . As in the one-dimensional case, the slopes (here
. As in the one-dimensional case, the slopes (here  ) depend strongly on the choice of point (here ) at which to derive. The derivative is therefore no longer a number, but a union of several numbers - in this example there are four - and these numbers are usually different for all inputs. It is generally also used for the derivation
) depend strongly on the choice of point (here ) at which to derive. The derivative is therefore no longer a number, but a union of several numbers - in this example there are four - and these numbers are usually different for all inputs. It is generally also used for the derivation

with which all "gradients" are gathered in a so-called matrix. This term is also called Jacobi matrix or functional matrix.
Example: If above  set, it can be shown that the following linear approximation is very good for very small changes in and
set, it can be shown that the following linear approximation is very good for very small changes in and

For example

and

In the very general case, if one has variables and output components, then combinatorially there are a total of  "gradients", i.e. partial derivatives. In the classical case
"gradients", i.e. partial derivatives. In the classical case  there is
there is  one gradient because of
one gradient because of  and in the example above
and in the example above  there are
there are  "gradients".
"gradients".




Diagram of the time-stretch function (in blue). If one second passes (in red), the distance traveled increases by 2 meters (in orange). Therefore the car moves with "2 meters per second". The speed corresponds exactly to the gradient. It should be noted that the gradient triangle can be reduced arbitrarily without changing anything in the proportion of height and base, so we could also talk about "2 nanometers per nanosecond" and so on. Therefore it is also reasonable to speak of an instantaneous velocity of 2 meters per second at any time.





History
→ Main article: Infinitesimal calculus#History of infinitesimal calculus.
The problem of differential calculus emerged as a tangent problem from the 17th century on. An obvious solution was to approximate the tangent to a curve by its secant over a finite (finite means here: greater than zero), but arbitrarily small interval. Thereby the technical difficulty had to be overcome to calculate with such an infinitesimally small interval width. The first beginnings of the differential calculus go back to Pierre de Fermat. Around 1628 he developed a method to determine extreme points of algebraic terms and to calculate tangents to conic sections and other curves. His "method" was purely algebraic. Fermat did not consider boundary crossings and certainly not derivatives. Nevertheless, his "method" can be interpreted and justified by modern means of analysis, and it has been shown to have inspired mathematicians such as Newton and Leibniz. A few years later, René Descartes chose a different algebraic approach by attaching a circle to a curve. This intersects the curve at two points close to each other; unless it touches the curve. This approach enabled him to determine the slope of the tangent line for special curves.
At the end of the 17th century, Isaac Newton and Gottfried Wilhelm Leibniz succeeded independently of each other in developing calculi that functioned without contradiction, using different approaches. While Newton approached the problem physically via the instantaneous velocity problem, Leibniz solved it geometrically via the tangent problem. Their work allowed abstraction from purely geometric notions and is therefore considered the beginning of calculus. They became known mainly through the book Analyse des Infiniment Petits pour l'Intelligence des Lignes Courbes by the nobleman Guillaume François Antoine, Marquis de L'Hospital, who took private lessons with Johann I Bernoulli and so published his research on calculus. It states:
"The scope of this calculus is immeasurable: it can be applied to mechanical as well as geometric curves; root signs cause it no difficulty and are often even pleasant to handle; it can be extended to as many variables as one could wish; the comparison of infinitely small quantities of all kinds succeeds effortlessly. And it permits an infinite number of surprising discoveries about curved as well as rectilinear tangents, questions De maximis & minimis, points of inflection and peaks of curves, evolutes, reflection and refraction caustics, &c. as we shall see in this book."
The derivation rules known today are based primarily on the works of Leonhard Euler, who coined the concept of function.
Newton and Leibniz worked with arbitrarily small positive numbers. This was already criticized by contemporaries as illogical, for example by George Berkeley in the polemical writing The analyst; or, a discourse addressed to an infidel mathematician. It was not until the 1960s that Abraham Robinson was able to place this use of infinitesimal quantities on a mathematically-axiomatically secure foundation with the development of non-standard analysis. Despite the prevailing uncertainty, however, the differential calculus was consistently developed, primarily because of its numerous applications in physics and other areas of mathematics. Symptomatic of the time was the prize competition published by the Prussian Academy of Sciences in 1784:
"... Higher geometry frequently uses infinitely large and infinitely small quantities; however, the ancient scholars carefully avoided the infinite, and some famous analysts of our time confess that the words infinite quantity are contradictory. The Academy, therefore, requires that one explain how so many correct propositions have arisen from a contradictory assumption, and that one give a safe and clear fundamental term which is likely to replace the infinite without making the calculation too difficult or too long ..."
It was not until the beginning of the 19th century that Augustin-Louis Cauchy succeeded in giving the differential calculus the logical rigor common today by departing from infinitesimals and defining the derivative as the limit of secant gradients (difference quotients). The definition of the limit value used today was finally formulated by Karl Weierstrass in 1861.


Derivative calculation
Calculating the derivative of a function is called differentiation; that is, differentiating that function.
To calculate the derivative of elementary functions (e.g. ,  , ...), one closely follows the definition given above, explicitly calculates a difference quotient, and then lets approach zero. However, this procedure is usually cumbersome. In teaching differential calculus, this type of calculation is therefore performed only a few times. Later one falls back on already known derivative functions or looks up derivatives of not quite so familiar functions in a table work (e.g. in the Bronstein-Semendjajew, see also table of derivative and trunk functions) and calculates the derivative of composite functions with the help of the derivative rules.
, ...), one closely follows the definition given above, explicitly calculates a difference quotient, and then lets approach zero. However, this procedure is usually cumbersome. In teaching differential calculus, this type of calculation is therefore performed only a few times. Later one falls back on already known derivative functions or looks up derivatives of not quite so familiar functions in a table work (e.g. in the Bronstein-Semendjajew, see also table of derivative and trunk functions) and calculates the derivative of composite functions with the help of the derivative rules.
Derivatives of elementary functions
For the exact calculation of the derivative functions of elementary functions, the difference quotient is formed and calculated in the limit transition  . Depending on the function type, different strategies must be used for this.
. Depending on the function type, different strategies must be used for this.
Natural potencies
The case can be handled by applying the first binomial formula:

In general, for a natural number with  must resort to the binomial theorem:
must resort to the binomial theorem:

where the polynomial  in two variables depends only on It follows:
in two variables depends only on It follows:

because obviously  holds .
holds .
Exponential function
For any the corresponding exponential function exp a  satisfies functional equation
satisfies functional equation 

This is due to the fact that a product of x factors with y factors a consists of x+y factors a in total. From this property it quickly becomes apparent that its derivative must agree with the original function except for one constant factor. Namely it is valid

Accordingly, only the existence of the derivative in  must be clarified, which is shown by
must be clarified, which is shown by

with the natural logarithm  of
of  . If there exists a base
. If there exists a base  property exp e ′
property exp e ′  , then even holds
, then even holds  for all , so
for all , so  Such an
Such an  is Euler's number: for it
is Euler's number: for it  holds and it is even uniquely determined by this property. Because of this distinguishing additional property,
holds and it is even uniquely determined by this property. Because of this distinguishing additional property,  abbreviated
abbreviated  simply as and is called a natural exponential function.
simply as and is called a natural exponential function.
Logarithm
For the logarithm  in base
in base  the law
the law

are used. This arises from the consideration: If u factors of a produce the value x and v factors of a produce the value y, so if  holds, then u+v factors of a produce the value xy. Thus for
holds, then u+v factors of a produce the value xy. Thus for

Besides  used that with also
used that with also  tends to 0. The natural logarithm, outside of school mathematics - especially in number theory - often just
tends to 0. The natural logarithm, outside of school mathematics - especially in number theory - often just  , otherwise sometimes
, otherwise sometimes  written , satisfies
written , satisfies  . This results in the law:
. This results in the law:

It is the inverse function of the natural exponential function, and its graph is obtained by mirroring the graph of the function  on the bisector
on the bisector  . From
. From  follows geometrically .
follows geometrically .
Sine and cosine
Required for the derivation laws behind sine and cosine are the addition theorems


and the relations


These can all be proved elementary-geometrically on the basis of the definitions of sine and cosine. With it results:

Similarly, one infers 
Derivation rules
Derivatives of composite functions, e.g.  or
or  , one traces back to the differentiation of elementary functions with the help of derivation rules (see also: Table of Derivative and Root Functions).
, one traces back to the differentiation of elementary functions with the help of derivation rules (see also: Table of Derivative and Root Functions).
The following rules can be used to trace the derivatives of composite functions to derivatives of simpler functions. Let , and (in the domain of definition) be differentiable real functions and a real number, then holds:

Factor rule

Sum rule

Product rule

Quotient rule

Reciprocal rule

Power rule
 , for natural numbers .
, for natural numbers .

Reversal rule
If a bijective function differentiableat with  , and its inverse function
, and its inverse function  at
at  , then holds:
, then holds:

If we mirror a point of  the graph of at the 1st bisector and thus obtain
the graph of at the 1st bisector and thus obtain  on , then the slope of in is the reciprocal of the slope of in .
on , then the slope of in is the reciprocal of the slope of in .
Logarithmic derivative
From the chain rule it follows for the derivative of the natural logarithm of a function :

A fraction of the form  is called a logarithmic derivative.
is called a logarithmic derivative.
Derivation of power and exponential functions
To  derive recall that powers with real exponents are defined in a roundabout way via the exponential function:
derive recall that powers with real exponents are defined in a roundabout way via the exponential function:  . Applying the chain rule and - for the inner derivative - the product rule yields
. Applying the chain rule and - for the inner derivative - the product rule yields
 .
.
Other elementary functions
If one has the rules of the calculus at hand, then derivative functions can be determined for many further elementary functions. This concerns especially important concatenations as well as inverse functions to important elementary functions.
General potencies
For any value the function  with
with  the derivative
the derivative  . This can be shown using the chain rule. If we use the notation
. This can be shown using the chain rule. If we use the notation  , the result is
, the result is

In particular, this results in derivation laws for general root functions: For any natural number , ![{\displaystyle {\sqrt[{n}]{x}}=x^{\frac {1}{n}}}](https://www.alegsaonline.com/image/87a4448e4847a987eb787a56c26c132147df63c2.svg) , and thus it follows
, and thus it follows
![{\displaystyle ({\sqrt[{n}]{x}})'=\left(x^{\frac {1}{n}}\right)'={\frac {1}{n}}x^{{\frac {1}{n}}-1}={\frac {1}{nx^{1-{\frac {1}{n}}}}}={\frac {\sqrt[{n}]{x}}{nx}}.}](https://www.alegsaonline.com/image/2cc95fcfa4db9d0ccb69764bc5f41574a3c85d31.svg)
The case  concerns the square root:
concerns the square root:

Tangent and cotangent
With the help of the quotient rule, derivatives of tangent and cotangent can also be determined via the derivative rules for sine and cosine. It applies

Pythagorean theorem  was used. Similarly, show
was used. Similarly, show  .
.
Arc sine and arc cosine
Arc sine and arc cosine define inverse functions of sine and cosine. Inside  their definition range
their definition range ![[-1,1]](https://www.alegsaonline.com/image/51e3b7f14a6f70e614728c583409a0b9a8b9de01.svg) the derivatives can be calculated using the inverse rule. For example, if
the derivatives can be calculated using the inverse rule. For example, if  it follows there
it follows there

Note that the main branch of the arc sine was considered and the derivative at the margins  not exist. For the arc cosine with
not exist. For the arc cosine with  analogously results in
analogously results in

in the open interval .
Arc tangent and arc cotangent
Arc tangent and arc cotangent define inverse functions of tangent and cotangent. In their domain of definition  the derivatives can be calculated using the inversion rule. For example, if
the derivatives can be calculated using the inversion rule. For example, if  then follows
then follows

For the arc cotangent, yields  analogously
analogously

Both derivative functions, like arc tangent and arc cotangent themselves, are defined everywhere in the real numbers.





Higher derivatives
If the derivative a function turn differentiable, then the second derivative of defined as the derivative of the first. In the same way, third, fourth etc. derivatives can be defined in the same way. Accordingly, a function can be differentiable once, differentiable twice, etc.
If the first derivative after time is a velocity, the second derivative can be interpreted as acceleration and the third derivative as jerk.
When politicians comment on the "decrease in the increase in the unemployment rate," they talk about the second derivative (change in the increase) to put the statement of the first derivative (increase in the unemployment rate) into perspective.
Higher derivatives can be written in several ways:

or in the physical case (for a derivative with respect to time)

For the formal denotation of arbitrary derivatives  , one also specifies
, one also specifies  and
and 
Higher differential operators
→ Main article: Differentiation class
If is a natural number and  open, then the space of functions continuously differentiable in
open, then the space of functions continuously differentiable in  -times is
-times is  denoted by The differential operator
denoted by The differential operator  thus induces a chain of linear mappings
thus induces a chain of linear mappings

and thus in general for  :
:

Here denotes  the space of continuous functions in . Exemplarily, if an derived once
the space of continuous functions in . Exemplarily, if an derived once  by applying , the result can in general be derived only
by applying , the result can in general be derived only  times, etc. Each space
times, etc. Each space  is an -algebra, since according to the sum rule and the product rule, respectively, sums and also products of
is an -algebra, since according to the sum rule and the product rule, respectively, sums and also products of  -times continuously differentiable functions are again -times continuously differentiable. Furthermore, the ascending chain of real inclusions is valid
-times continuously differentiable functions are again -times continuously differentiable. Furthermore, the ascending chain of real inclusions is valid

because obviously every function which is at least -times continuously differentiable is also -times continuously differentiable etc., but the functions show

exemplary examples for functions from  if - which is possible without restriction of generality -
if - which is possible without restriction of generality -  is assumed.
is assumed.
Higher derivation rules
Leibniz's rule
The derivative of -th order for a product of two -times differentiable functions and is given by
 .
.
The expressions of the form  appearing here are binomial coefficients. The formula is a generalization of the product rule.
appearing here are binomial coefficients. The formula is a generalization of the product rule.
Faà di Bruno formula
This formula allows the closed representation of the -th derivative of the composition of two -times differentiable functions. It generalizes the chain rule to higher derivatives.
Taylor formulas with remainder
→ Main article: Taylor formula
If a function continuously differentiable in an interval 
 -times continuously differentiable, then for all and from the so-called Taylor formula holds:
-times continuously differentiable, then for all and from the so-called Taylor formula holds:

with the -th Taylor polynomial at the development point

and the -th remainder element

with a ξ  . A function that can be differentiated any number of times is called a smooth function. Since it has all derivatives, the Taylor formula given above can be extended to the Taylor series of with development point
. A function that can be differentiated any number of times is called a smooth function. Since it has all derivatives, the Taylor formula given above can be extended to the Taylor series of with development point

However, not every smooth function can be represented by its Taylor series, see below.
Smooth functions
→ Main article: Smooth function
Functions which are differentiable arbitrarily often at any point of their definition space are also called smooth functions. The set of all functions in an open set smooth functions  is usually
is usually  denoted by It carries the structure of an -algebra (scalar multiples, sums and products of smooth functions are smooth again) and is given by
denoted by It carries the structure of an -algebra (scalar multiples, sums and products of smooth functions are smooth again) and is given by

where denotes all functions in -times continuously differentiable. Often one finds the term sufficiently smooth in mathematical considerations. This means that the function is differentiable at least as often as it is necessary to carry out the current train of thought.
Analytical functions
→ Main article: Analytic function
The upper notion of smoothness can be further tightened. A function is called real analytic if it can be locally developed into a Taylor series at any point, i.e.

for all  and all sufficiently small values of
and all sufficiently small values of  . Analytic functions have strong properties and receive special attention in complex analysis. Accordingly, complex analytic functions rather than real analytic functions are studied there. Their set is usually
. Analytic functions have strong properties and receive special attention in complex analysis. Accordingly, complex analytic functions rather than real analytic functions are studied there. Their set is usually  denoted by and it holds
denoted by and it holds  . In particular, every analytic function is smooth, but not vice versa. Thus, the existence of all derivatives is not sufficient for the Taylor series to represent the function, as shown by the following counterexample.
. In particular, every analytic function is smooth, but not vice versa. Thus, the existence of all derivatives is not sufficient for the Taylor series to represent the function, as shown by the following counterexample.

of a non-analytic smooth function. All real derivatives of this function vanish in 0, but it is not the zero function. Therefore, it is not represented by its Taylor series at the point 0.
Applications
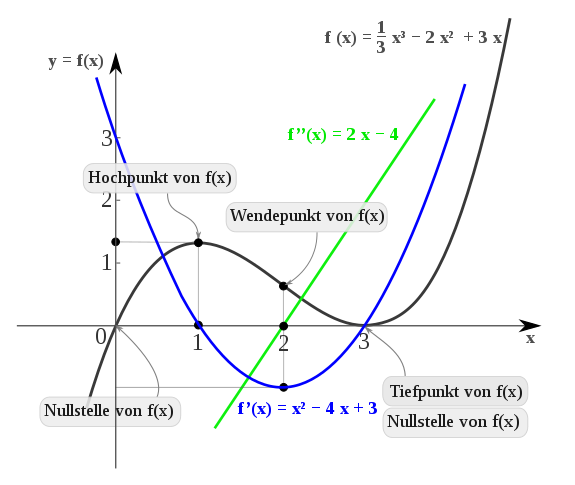
An important application of differential calculus in one variable is the determination of extreme values, usually for the optimization of processes, such as in the context of cost, material or energy expenditure. The differential calculus provides a method to find extreme points without having to search numerically under effort. One makes use of the fact that at a local extreme necessarily the first derivative of the function must be equal to 0. Thus, must  hold if is a local extreme. However, the other way around, does not yet imply that a maximum or minimum. In this case, more information is needed to make a definite decision, which is usually possible by looking at higher derivatives at
hold if is a local extreme. However, the other way around, does not yet imply that a maximum or minimum. In this case, more information is needed to make a definite decision, which is usually possible by looking at higher derivatives at
A function can have a maximum or minimum value without the derivative existing at this point, but in this case the differential calculus cannot be used. Therefore, in the following, only at least locally differentiable functions will be considered. As an example we take the polynomial function with the function term

The figure shows the course of the graphs of , and  .
.
Horizontal tangents
Given a function  with
with  at a point
at a point  its largest value, then it is true for all this interval
its largest value, then it is true for all this interval  , and if is differentiable at the point , then the derivative there can only be zero: . A corresponding statement holds if takes the smallest value in
, and if is differentiable at the point , then the derivative there can only be zero: . A corresponding statement holds if takes the smallest value in
Geometric interpretation of this theorem of Fermat is that the graph of the function in local extreme points has a tangent parallel to the axis, also called horizontal tangent.
Thus, for differentiable functions, it is a necessary condition for the existence of an extreme point that the derivative at the point in question takes the value 0:

Conversely, however, the fact that the derivative has the value zero at a point does not mean that it is an extreme point; there could also be a saddle point, for example. A list of different sufficient criteria, whose fulfillment lets conclude certainly on an extreme point, can be found in the article extreme value. These criteria mostly use the second or even higher derivatives.
Condition in the example
In the example

It follows that  holds
holds  exactly for
exactly for  and The function values at these points are
and The function values at these points are  and
and  , i.e., the curve has
, i.e., the curve has  horizontal tangents at points
horizontal tangents at points  and and only at these.
and and only at these.
Since the sequence

consists alternately of small and large values, there must be a high and a low point in this range. According to Fermat's theorem, the curve has a horizontal tangent in these points, so only the points determined above are possible: So is a high point and a low point.
Curve discussion
→ Main article: Curve discussion
With the help of the derivatives further properties of the function can be analyzed, like the existence of turning and saddle points, the convexity or the monotonicity already mentioned above. The execution of these investigations is the subject of the curve discussion.
Term transformations
Besides the determination of the slope of functions, the differential calculus is by its calculus an essential aid in term transformation. Here one detaches oneself from any connection with the original meaning of the derivative as increase. If one has recognized two terms as equal, further (looked for) identities can be won by differentiation from it. An example may clarify this:
From the known partial sum

of the geometric series shall be the sum

can be calculated. This is done by differentiation with the help of the quotient rule:

Alternatively, the identity is obtained by multiplying out and then triple telescoping, but this is not so easy to see through.
Central statements of the differential calculus of one variable
Fundamental theorem of analysis
→ Main article: Fundamental theorem of calculus
Leibniz's essential achievement was the realization that integration and differentiation are related. He formulated this in the main theorem of differential and integral calculus, also called the fundamental theorem of analysis, which states:
If  an interval,
an interval,  is a continuous function and
is a continuous function and  any number from , then the function
any number from , then the function

continuously differentiable, and its derivative  is equal to .
is equal to .
Herewith a guidance for integrating is given: We are looking for a function whose derivative is the integrand Then holds:

Mean value theorem of the differential calculus
→ Main article: Mean value theorem of differential calculus
Another central theorem of differential calculus is the mean value theorem, which was proved by Cauchy in 1821.
Let ![f\colon [a,b]\to \mathbb {R}](https://www.alegsaonline.com/image/c5ab61178bf5349838758ffe3d96135406ed0245.svg) a function that operates on the closed interval
a function that operates on the closed interval ![[a,b]](https://www.alegsaonline.com/image/9c4b788fc5c637e26ee98b45f89a5c08c85f7935.svg) (with
(with  defined and continuous. Moreover, let the function be
defined and continuous. Moreover, let the function be  differentiable in the open interval Under these conditions, there exists at least one such that
differentiable in the open interval Under these conditions, there exists at least one such that

applies - geometrically-illustrative: Between two intersections of a secant there is a point on the curve with a tangent parallel to the secant.
Monotonicity and differentiability
If : ( a differentiable function with  for all
for all  , then the following statements hold:
, then the following statements hold:
- The function is strictly monotonic.
- It is
 with any
with any - The inverse function
 exists, is differentiable and satisfies
exists, is differentiable and satisfies  .
.
From this it can be deduced that a continuously differentiable function  whose derivative vanishes nowhere, already
whose derivative vanishes nowhere, already  defines a diffeomorphism between the intervals and In several variables the analogous statement is false. Thus, the derivative of the complex exponential function
defines a diffeomorphism between the intervals and In several variables the analogous statement is false. Thus, the derivative of the complex exponential function  , namely itself, at no point, but it is not a (globally) injective mapping
, namely itself, at no point, but it is not a (globally) injective mapping  . Note that this is given as a higher dimensional real function
. Note that this is given as a higher dimensional real function  can be conceived as
can be conceived as  a two-dimensional -vector space.
a two-dimensional -vector space.
However, Hadamard's theorem provides a criterion for showing in some cases that a continuously differentiable function  is a homeomorphism.
is a homeomorphism.
The rule of de L'Hospital
→ Main article: Rule of de L'Hospital
As an application of the Mean Value Theorem, a relation can be derived that allows in some cases to compute indefinite terms of the form or } .
.
Let  differentiable and have no zero. Furthermore either
differentiable and have no zero. Furthermore either

or
 .
.
Then applies

if the last limit in  exists.
exists.
Differential calculus with function sequences and integrals
In many analytical applications one is not dealing with a function but with a sequence  . It must be clarified to what extent the derivative operator is compatible with processes such as limits, sums, or integrals.
. It must be clarified to what extent the derivative operator is compatible with processes such as limits, sums, or integrals.
Limit functions
Given a convergent differentiable sequence of functions it is in general not possible to draw conclusions about the limit of the sequence  , even if converges uniformly. The analogous statement in integral calculus, on the other hand, is correct: if convergence is uniform, the limit and integral can be interchanged, at least if the limit function is "benign".
, even if converges uniformly. The analogous statement in integral calculus, on the other hand, is correct: if convergence is uniform, the limit and integral can be interchanged, at least if the limit function is "benign".
From this fact at least the following can be concluded: Let ![{\displaystyle f_{n}\colon [a,b]\to \mathbb {R} }](https://www.alegsaonline.com/image/b32ac944f464748dfb697057d3788497bfabb6fe.svg) a sequence of continuously differentiable functions such that the sequence of derivatives
a sequence of continuously differentiable functions such that the sequence of derivatives ![{\displaystyle f_{n}'\colon [a,b]\to \mathbb {R} }](https://www.alegsaonline.com/image/fa20a73b34f9d8b5ab0dd50731c0f34dcabbb59f.svg) uniformly against a function
uniformly against a function ![{\displaystyle g\colon [a,b]\to \mathbb {R} }](https://www.alegsaonline.com/image/38132af5ea7cd916293fe93f29187bd461a5e270.svg) converges. Let it also hold that the sequence converges
converges. Let it also hold that the sequence converges  for at least one point
for at least one point ![x_{0}\in [a,b]](https://www.alegsaonline.com/image/06636653315ee7c3b5dc9bdb6ac3fb8cccadc145.svg) Then converges already uniform against a differentiable function and it holds that
Then converges already uniform against a differentiable function and it holds that  .
.
Swap with infinite series
Let a sequence of continuously differentiable functions such that the series  converges, where
converges, where ![{\displaystyle ||f_{n}'||_{\infty }:=\sup _{x\in [a,b]}|f_{n}'(x)|}](https://www.alegsaonline.com/image/c15371c13ae76eca92cdd6495b526d331581d44c.svg) denotes the supremum norm. Moreover, if the sequence converges
denotes the supremum norm. Moreover, if the sequence converges  for an , then the sequence converges
for an , then the sequence converges  uniformly against a differentiable function, and it holds that
uniformly against a differentiable function, and it holds that

The result goes back to Karl Weierstrass.
Swap with integration
Let ![{\displaystyle f\colon [a,b]\times [c,d]\to \mathbb {R} }](https://www.alegsaonline.com/image/7d985fd7a6c6afcc39f2bfa732015f9c55ebf223.svg) is a continuous function, so that the partial derivative
is a continuous function, so that the partial derivative

exists and is continuous. Then also

differentiable, and it holds

This rule is also called Leibniz's rule.
Differential calculus over the complex numbers
So far, only real functions have been discussed. However, all treated rules can be transferred to functions with complex inputs and values. This has the background that the complex numbers form a body just like the real numbers, so addition, multiplication and division are explained there. This additional structure forms the decisive difference to an approach of multidimensional real derivatives, if merely as a two-dimensional -vector space. Furthermore, the Euclidean distance notions of the real numbers (see also Euclidean Space) can be naturally transferred to complex numbers. This allows an analogous definition and treatment of the terms important for differential calculus, such as sequence and limit.
Thus, if  open,
open,  a complex-valued function, then is called
a complex-valued function, then is called  complex differentiable at the point if the limit is
complex differentiable at the point if the limit is

exists. This is  denoted by and called (complex) derivative of at the position
denoted by and called (complex) derivative of at the position  Accordingly, it is possible to carry the notion of linearization further into the complex: the derivative is the "slope" of the linear function that optimally approximates at However, it should be noted that the value in the limit can take not only real numbers, but also complex numbers (close to 0). This has the consequence that the term of the complex differentiability is substantially more restrictive than that of the real differentiability. While in the real only two directions had to be considered in the difference quotient, in the complex there are infinitely many directions, because they do not span a straight line but a plane. For example, the magnitude function
Accordingly, it is possible to carry the notion of linearization further into the complex: the derivative is the "slope" of the linear function that optimally approximates at However, it should be noted that the value in the limit can take not only real numbers, but also complex numbers (close to 0). This has the consequence that the term of the complex differentiability is substantially more restrictive than that of the real differentiability. While in the real only two directions had to be considered in the difference quotient, in the complex there are infinitely many directions, because they do not span a straight line but a plane. For example, the magnitude function  nowhere complex differentiable. A complex function is complex differentiable at a point exactly if it satisfies the Cauchy-Riemann differential equations there.
nowhere complex differentiable. A complex function is complex differentiable at a point exactly if it satisfies the Cauchy-Riemann differential equations there.
In spite of (or just because of) the much more restrictive concept of complex differentiability, all usual calculation rules of the real differential calculus are transferred to the complex differential calculus. This includes the derivation rules, for example the sum, product and chain rule, as well as the inverse rule for inverse functions. Many functions, such as powers, the exponential function or the logarithm, have natural continuations into the complex numbers and continue to possess their characteristic properties. From this point of view, the complex differential calculus is identical to its real analog.
If a function is complex differentiable in all of , it is also called a "in holomorphic function". Holomorphic functions have significant properties. For example, any holomorphic function is already differentiable (at any point) any number of times. The resulting classification question of holomorphic functions is the subject of function theory. It turns out that in the complex-one-dimensional case the term holomorphic is exactly equivalent to the term analytic. Accordingly, every holomorphic function is analytic, and vice versa. If a function is holomorphic even in all of is called entire. Examples of entire functions are the power functions  with natural numbers and
with natural numbers and  ,
,  and
and  .
.
Differential calculus of multidimensional functions
All previous explanations were based on a function in one variable (i.e. with a real or complex number as argument). Functions which map vectors to vectors or vectors to numbers can also have a derivative. However, a tangent to the function graph in these cases is no longer uniquely determined, since there are many different directions. Here, therefore, an extension of the previous derivation concept is necessary.
Multidimensional differentiability and the Jacobi matrix
Directional derivative
→ Main article: Directional derivative
Let  open,
open,  a function,
a function,  and
and  a (directional) vector. Due to the openness of there exists an ε
a (directional) vector. Due to the openness of there exists an ε  0 +
0 +  all | h |
all | h |  , which is why the function
, which is why the function  with
with  is well-defined. If this function is
is well-defined. If this function is  differentiable in , its derivative is called the directional derivative of at the point in the direction
differentiable in , its derivative is called the directional derivative of at the point in the direction  and is usually
and is usually  denoted by It holds:
denoted by It holds:

There is a connection between the directional derivative and the Jacobi matrix. If is differentiable, then there exists and it holds in a neighborhood of :

where the notation  denotes the corresponding Landau symbol.
denotes the corresponding Landau symbol.
As an example, consider a function  is considered, that is, a scalar field. This could be a temperature function: Depending on the location, the temperature in the room is measured to assess how effective the heating is. If the thermometer is moved in a certain direction of the room, there is a change in temperature. This corresponds exactly to the corresponding directional derivative.
is considered, that is, a scalar field. This could be a temperature function: Depending on the location, the temperature in the room is measured to assess how effective the heating is. If the thermometer is moved in a certain direction of the room, there is a change in temperature. This corresponds exactly to the corresponding directional derivative.
Partial derivatives
→ Main article: Partial derivative
The directional derivatives in special directions  namely into those of the coordinate axes with length , are
namely into those of the coordinate axes with length , are  called the partial derivatives.
called the partial derivatives.
In total, partial derivatives can be calculated for a function in variables:

The individual partial derivatives of a function can also be written as a gradient or nabula vector:

Mostly the gradient is written as a row vector (i.e. "lying"). However, in some applications, especially in physics, the notation as column vector (i.e. "standing") is also common. Partial derivatives can themselves be differentiable and their partial derivatives can then be arranged in the so-called Hessian matrix.
Total differentiability
→ Main article: Total differentiability
A function  with
with  , where is an open set, is called totally differentiable (or just differentiable, sometimes Fréchet-differentiable) at a point if a linear mapping
, where is an open set, is called totally differentiable (or just differentiable, sometimes Fréchet-differentiable) at a point if a linear mapping  exists such that
exists such that

is valid. For the one-dimensional case this definition agrees with the one given above. The linear mapping  is uniquely determined if it exists, so in particular it is independent of the choice of equivalent norms. The tangent is therefore abstracted by the local linearization of the function. The matrix representation of the first derivative of is called a Jacobi matrix. It is a
is uniquely determined if it exists, so in particular it is independent of the choice of equivalent norms. The tangent is therefore abstracted by the local linearization of the function. The matrix representation of the first derivative of is called a Jacobi matrix. It is a  matrix. For
matrix. For  we get the gradient described above.
we get the gradient described above.
The following relationship exists between the partial derivatives and the total derivative: If the total derivative exists in a point, then all partial derivatives also exist there. In this case the partial derivatives agree with the coefficients of the Jacobi matrix:

Conversely, the existence of partial derivatives at a point not necessarily imply total differentiability, not even continuity. However, if the partial derivatives are also continuous in a neighborhood of , then the function is also totally differentiable in
Calculation rules of the multidimensional differential calculus
Chain rule
→ Main article: Multidimensional chain rule
Let and  open and and
open and and  differentiable
differentiable  in or where
in or where  . Then
. Then  with
with  in differentiable with Jacobi matrix
in differentiable with Jacobi matrix

In other words, the Jacobi matrix of the composition  is the product of the Jacobi matrices of and . Note that the order of the factors matters, unlike in the classical one-dimensional case.
is the product of the Jacobi matrices of and . Note that the order of the factors matters, unlike in the classical one-dimensional case.
Product rule
See also: Multidimensional product rule
Using the chain rule, the product rule can be generalized to real-valued functions with higher dimensional domain of definition. If open and are  both differentiable in , then it follows.
both differentiable in , then it follows.

or in gradient notation

Function sequences
Let open. Let denote  a sequence of continuously differentiable functions
a sequence of continuously differentiable functions  such that there exist functions and
such that there exist functions and  (where
(where  the space of linear mappings from
the space of linear mappings from  to
to  ) such that the following holds:
) such that the following holds:
 converges pointwise to ,
converges pointwise to , converges locally uniformly to .
converges locally uniformly to .
Then is continuously differentiable on and it holds  .
.
Implicit differentiation
→ Main article: Implicit differentiation
If a function 
 given by an implicit equation , it follows from the multidimensional chain rule that applies to functions of several variables,
given by an implicit equation , it follows from the multidimensional chain rule that applies to functions of several variables,

For the derivative of the function get therefore

where  and
and 
Central theorems of the differential calculus of several variables
Black set
→ Main article: Black's theorem
The differentiation order is irrelevant for the calculation of partial derivatives of higher order, if all partial derivatives up to this order (inclusive) are continuous. This means concretely: If open and the function twice continuously differentiable (i.e., all twofold partial derivatives exist and are continuous), then for all  and
and  :
:

The theorem becomes false if the continuity of the twofold partial derivatives is omitted.
Theorem of the implicit function
→ Main article: Theorem of the implicit function
The implicit function theorem states that functional equations are solvable if the Jacobian matrix is locally invertible with respect to certain variables.
Mean value set
Via the higher dimensional mean value theorem it is possible to estimate a function along a connecting line if the derivatives there are known. Let open and differentiable. Given also two points  such that the connecting distance
such that the connecting distance  is a subset of Then the mean value theorem postulates the inequality:
is a subset of Then the mean value theorem postulates the inequality:

However, a more precise statement is possible for the case of real-valued functions in several variables, see also Mean Value Theorem for Real-Valued Functions of Several Variables.
Higher derivatives in the multidimensional
Higher derivatives can also be considered in the case of higher dimensional functions. However, the concepts have some strong differences to the classical case, which become apparent especially in the case of several variables. Already the Jacobi matrix lets recognize that the derivative of a higher dimensional function at a point does not have to have the same shape as the function value there. If now the first derivative  derived again, the renewed "Jacobi matrix" is in general an even more extensive object. The concept of multilinear mappings or tensor is required to describe it. If ∂
derived again, the renewed "Jacobi matrix" is in general an even more extensive object. The concept of multilinear mappings or tensor is required to describe it. If ∂  , then ∂ assigns to
, then ∂ assigns to  each point a matrix (linear mapping from to ). Inductively one defines for the higher derivatives
each point a matrix (linear mapping from to ). Inductively one defines for the higher derivatives

where  is the space of
is the space of  -multilinear mappings of
-multilinear mappings of  to denotes. Analogously to the one-dimensional case, one defines the spaces of -mal continuously differentiable functions on by
to denotes. Analogously to the one-dimensional case, one defines the spaces of -mal continuously differentiable functions on by  , and the smooth function via
, and the smooth function via

Also the concepts of Taylor formulas and Taylor series can be generalized to the higher dimensional case, see also Taylor formula in the multidimensional or multidimensional Taylor series.
Applications
Error calculation
An application example of the differential calculus of several variables concerns the error calculation, for example in the context of experimental physics. While in the simplest case the quantity to be determined can be measured directly, it will usually be the case that it results from a functional relationship of quantities that are easier to measure. Typically, every measurement has a certain uncertainty, which one tries to quantify by specifying the measurement error.
For example, denotes  with
with  the volume of a cuboid, the result could be
the volume of a cuboid, the result could be  determined experimentally by taking length
determined experimentally by taking length  , width ,
, width ,  and height individually. If the errors Δ
and height individually. If the errors Δ  , Δ
, Δ  and Δ
and Δ  occur, then the following applies to the error in the volume calculation:
occur, then the following applies to the error in the volume calculation:

In general, if a quantity to be measured is functionally related to individually measured quantities  by
by  and for each of whose measurements the errors Δ
and for each of whose measurements the errors Δ  arise, the error of the quantity calculated from them is about
arise, the error of the quantity calculated from them is about

will lie. Here, the vector  denotes the exact terms of the individual measurements.
denotes the exact terms of the individual measurements.
Solution approximation of equation systems
Many higher systems of equations cannot be solved algebraically closed. In some cases, however, one can at least determine an approximate solution. If the system is  given by , with a continuously differentiable function
given by , with a continuously differentiable function  , then the iteration rule converges to.
, then the iteration rule converges to.

under certain conditions against a zero. Here  denotes the inverse of the Jacobi matrix to . The process is a generalization of the classical one-dimensional Newton method. However, the computation of these inverses at each step is costly. Under degradation of the convergence rate, in some cases the modification can be made instead of
denotes the inverse of the Jacobi matrix to . The process is a generalization of the classical one-dimensional Newton method. However, the computation of these inverses at each step is costly. Under degradation of the convergence rate, in some cases the modification can be made instead of  , thus only one matrix has to be inverted.
, thus only one matrix has to be inverted.
Extreme value tasks
Also for the curve discussion of functions  the finding of minima or maxima, in summary extrema, is an essential concern. The multidimensional differential calculus provides ways to determine them, provided that the function under consideration is twice continuously differentiable. Analogous to the one-dimensional, the necessary condition for the existence of extrema states that in the point
the finding of minima or maxima, in summary extrema, is an essential concern. The multidimensional differential calculus provides ways to determine them, provided that the function under consideration is twice continuously differentiable. Analogous to the one-dimensional, the necessary condition for the existence of extrema states that in the point  all partial derivatives must be 0, thus
all partial derivatives must be 0, thus

for all  . This criterion is not sufficient, but serves to identify these critical points as possible candidates for extrema. Under determination of the Hessian matrix, the second derivative, it can be decided afterwards in some cases what kind of extreme point it is. In contrast to the one-dimensional, the variety of shapes of critical points is larger. By means of a principal axis transformation, i.e. a detailed investigation of the eigenvalues, of the quadratic form given by a multidimensional Taylor expansion in the point under consideration, the different cases can be classified.
. This criterion is not sufficient, but serves to identify these critical points as possible candidates for extrema. Under determination of the Hessian matrix, the second derivative, it can be decided afterwards in some cases what kind of extreme point it is. In contrast to the one-dimensional, the variety of shapes of critical points is larger. By means of a principal axis transformation, i.e. a detailed investigation of the eigenvalues, of the quadratic form given by a multidimensional Taylor expansion in the point under consideration, the different cases can be classified.
Optimization under constraints
Often in optimization problems, the objective function only on a subset  , where
, where  is determined by so-called constraints. One method that can be used to solve such problems is the Lagrange multiplier rule. This uses the multidimensional differential calculus and can even be extended to inequality constraints.
is determined by so-called constraints. One method that can be used to solve such problems is the Lagrange multiplier rule. This uses the multidimensional differential calculus and can even be extended to inequality constraints.
Example from microeconomics
In microeconomics, for example, different types of production functions are analyzed in order to gain insights for macroeconomic relationships. Here, the typical behavior of a production function is of particular interest: How does the dependent variable output (e.g. output of an economy), if the input factors (here: labor and capital) are increased by an infinitesimally small unit?
One basic type of production function is the neoclassical production function. It is characterized, among other things, by the fact that output increases with each additional input, but that the increases are decreasing. For example, let the Cobb-Douglas function for an economy be
 with α
with α
is decisive. At any point in time,  output is produced in the economy using the production factors labor and capital help of
output is produced in the economy using the production factors labor and capital help of a given technology level The first derivative of this function with respect to the factors of production yields:
a given technology level The first derivative of this function with respect to the factors of production yields:

 .
.
Since the partial derivatives can only become positive due to the constraint α, we see that output increases as the respective input factors increase. The 2nd order partial derivatives yield:

 .
.
They will be negative for all inputs, so growth rates fall. Thus, one could say that as inputs increase, output increases less than proportionally. The relative change in output with respect to a relative change in input is  given here by the elasticity η Here, η denotes
given here by the elasticity η Here, η denotes  the production elasticity of capital, which in this production function corresponds to
the production elasticity of capital, which in this production function corresponds to  the exponent α which in turn represents the capital income ratio. Consequently, output increases by the capital income ratio for an infinitesimally small increase in capital.
the exponent α which in turn represents the capital income ratio. Consequently, output increases by the capital income ratio for an infinitesimally small increase in capital.
Advanced theories
Differential equations
→ Main article: Differential equation
An important application of differential calculus is in the mathematical modeling of physical processes. Growth, motion, or forces all involve derivatives, so their formulaic description must include differentials. Typically, this leads to equations in which derivatives of an unknown function appear, so-called differential equations.
For example, the Newtonian law of motion links

the acceleration  a body with its mass and the force acting on it
a body with its mass and the force acting on it  . The basic problem of mechanics is therefore to derive the position function of a body from a given acceleration. This problem, an inverse of twofold differentiation, has the mathematical form of a second-order differential equation. The mathematical difficulty of this problem stems from the fact that location, velocity, and acceleration are vectors that generally do not point in the same direction, and that the force may depend on time and location
. The basic problem of mechanics is therefore to derive the position function of a body from a given acceleration. This problem, an inverse of twofold differentiation, has the mathematical form of a second-order differential equation. The mathematical difficulty of this problem stems from the fact that location, velocity, and acceleration are vectors that generally do not point in the same direction, and that the force may depend on time and location 
Since many models are multidimensional, the partial derivatives explained above are often very important in the formulation, with which partial differential equations can be formulated. Mathematically compact, these are described and analyzed by means of differential operators.
Differential Geometry
→ Main article: Differential geometry
The central theme of differential geometry is the extension of classical analysis to higher geometric objects. These look locally like, for example, the Euclidean space , but can have a different shape globally. The notion behind this phenomenon is the manifold. Differential geometry is used to study questions about the nature of such objects - differential calculus remains the central tool. The object of study is often the distances between points or the volumes of figures. For example, it can be used to determine and measure the shortest possible path between two points on a curved surface, called the geodesic. For the measurement of volumes the term differential form is needed. Differential forms allow, among other things, coordinate-independent integration.
Both the theoretical results and methods of differential geometry have significant applications in physics. For example, Albert Einstein described his theory of relativity in differential geometric terms.
Generalizations
In many applications it is desirable to be able to form derivatives also for continuous or even discontinuous functions. For example, a wave breaking on a beach can be modeled by a partial differential equation, but the function of the height of the wave is not even continuous. For this purpose, in the middle of the 20th century, the notion of derivative was generalized to the space of distributions and a weak derivative was defined there. Closely connected with this is the notion of Sobolev space.
The notion of derivative as linearization can be applied analogously to functions between two normable topological vector spaces  and
and  (see main articles Fréchet derivative, Gâteaux differential, Lorch derivative): is called Fréchet differentiable in ξ
(see main articles Fréchet derivative, Gâteaux differential, Lorch derivative): is called Fréchet differentiable in ξ  Fréchet-differentiable if there
Fréchet-differentiable if there  exists a continuous linear operator such that.
exists a continuous linear operator such that.
 .
.
A transfer of the notion of derivative to rings other than and (and algebras above it) leads to derivation.
Questions and answers
Q: What is differential calculus?
A: Differential calculus is a branch of calculus that studies the rate of change of a variable compared to another variable, by using functions.
Q: How does it work?
A: Differential calculus allows us to find out how a shape changes from one point to the next without needing to divide the shape into an infinite number of pieces.
Q: Who developed differential calculus?
A: Differential calculus was developed in the 1670s and 1680s by Sir Isaac Newton and Gottfried Leibniz.
Q: What is integral calculus?
A: Integral calculus is the opposite of differential calculus. It is used for finding areas under curves and volumes of solids with curved surfaces.
Q: When was differential calculus developed?
A: Differential calculus was developed in the 1670s and 1680s by Sir Isaac Newton and Gottfried Leibniz.
Q: What are some applications of differential calculus?
A: Some applications of differential calculus include calculating velocity, acceleration, maximum or minimum values, optimization problems, slope fields, etc.
Q: Why do we use differential calculus instead of dividing shapes into an infinite number of pieces?
A: We use differential calculus instead because it allows us to find out how a shape changes from one point to the next without needing to divide the shape into an infinite number of pieces.
Related articles
Author
AlegsaOnline.com Differential calculus: rates of change, derivatives, and applications Leandro Alegsa
URL: https://en.alegsaonline.com/art/27342